$ docker run hello-world
Unable to find image 'hello-world:latest' locally
latest: Pulling from library/hello-world
2c7ed585684a: Pull complete
Digest: sha256:df5f5184104426b65967e016ff2ac0bfcd44ad7899ca3bbcf8e44e4461491a9e
Status: Downloaded newer image for hello-world:latest
Hello from Docker!
This message shows that your installation appears to be working correctly.
To generate this message, Docker took the following steps:
1. The Docker client contacted the Docker daemon.
2. The Docker daemon pulled the "hello-world" image from the Docker Hub.
(arm32v7)3. The Docker daemon created a new container from that image which runs the
executable that produces the output you are currently reading.
4. The Docker daemon streamed that output to the Docker client, which sent it
to your terminal.
To try something more ambitious, you can run an Ubuntu container with:
$ docker run -it ubuntu bash
Share images, automate workflows, and more with a free Docker ID:
https://hub.docker.com/
For more examples and ideas, visit:
https://docs.docker.com/get-started/
上記のようにhello-worldコンテナが実行できれば成功です。
おわりに
今回は、Raspberry PiにDockerをインストールする方法をまとめました。
Raspberry Pi OSのアーキテクチャ(Arm32)には気を付ける必要がありますが、これでコンテナをRaspberry Piで動かすことが出来るようになりました。
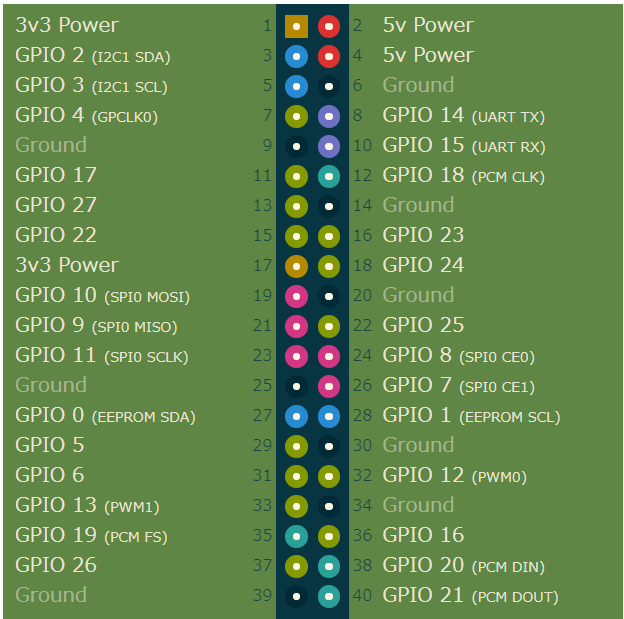
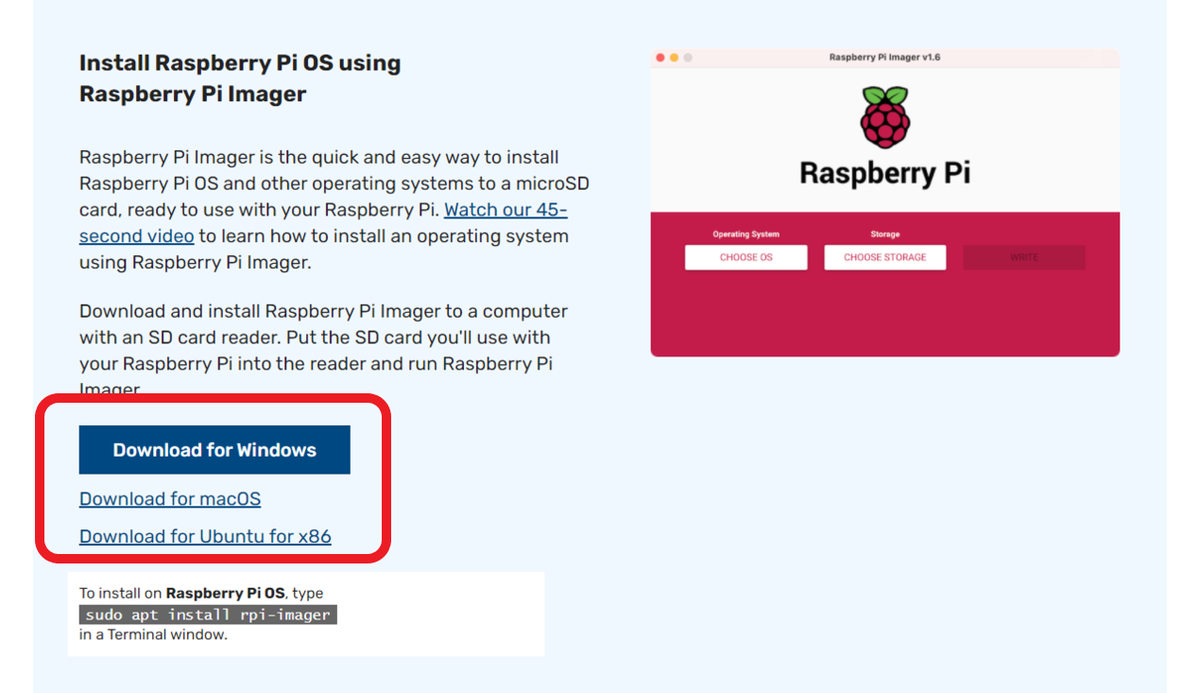
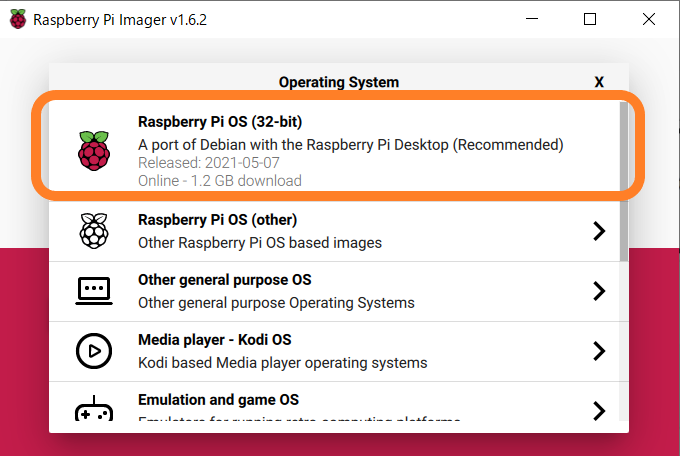
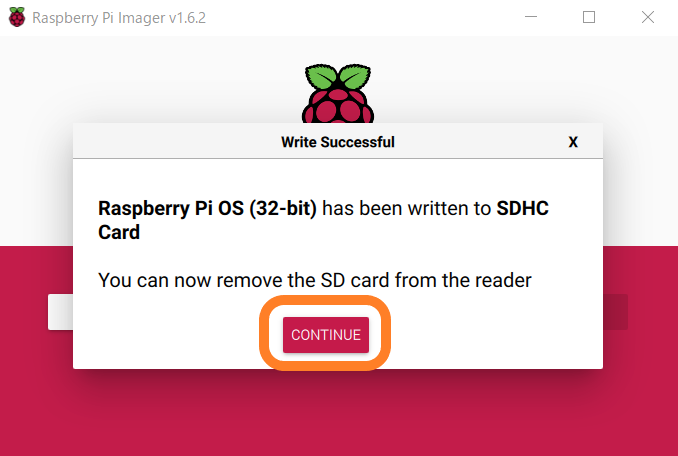
パーツが揃ったら、Raspberry Pi Imagerを使ってmicroSDにRaspberry Pi OSを書き込みます。
Raspberry Pi Imagerとは、Raspberry Pi OSをmicroSDに自動でインストールしてくれるアプリケーションです。
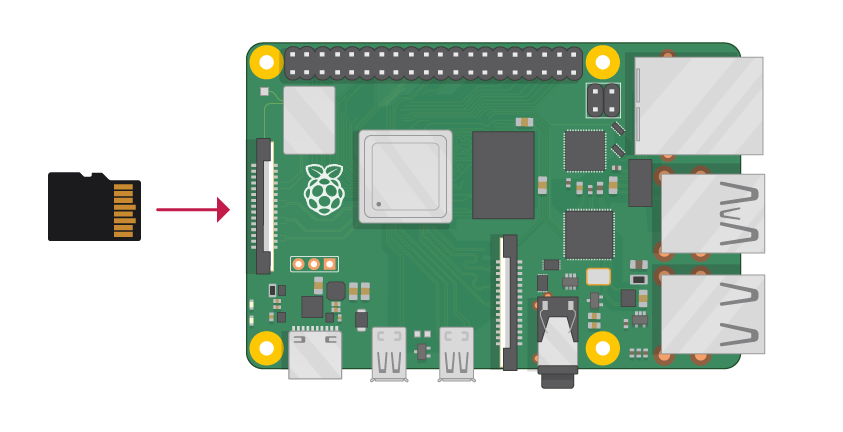
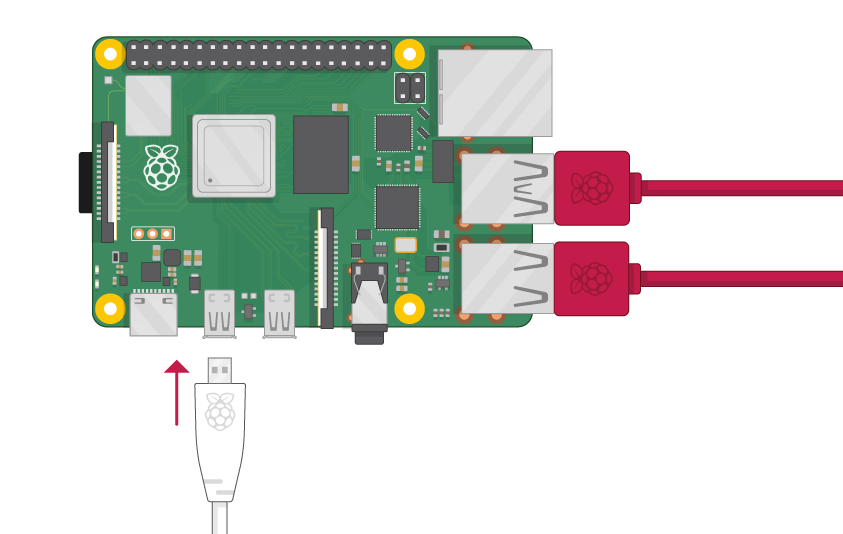
書き込み後のmicroSDをRaspberry Piに挿して電源を付ければ、OSを起動することが出来ます。
Raspberry Pi Imager is the quick and easy way to install Raspberry Pi OS and other operating systems to a microSD card, ready to use with your Raspberry Pi.
length
The builtin function length gets the length of various different types of value:
· The length of a string is the number of Unicode codepoints it contains (which will be the same as its JSON-encoded length in bytes if it´s pure ASCII).
· The length of an array is the number of elements.
· The length of an object is the number of key-value pairs.
· The length of null is zero.
Return disk usage statistics about the given path as a named tuple with the attributes total, used and free, which are the amount of total, used and free space, in bytes. path may be a file or a directory.
The following cp command uploads a local file stream from standard input to a specified bucket and key:
aws s3 cp - s3://mybucket/stream.txt
標準出力:
The following cp command downloads an S3 object locally as a stream to standard output. Downloading as a stream is not currently compatible with the --recursive parameter:
aws s3 cp s3://mybucket/stream.txt -
$ man grep
-r, --recursive
Read all files under each directory, recursively, following
symbolic links only if they are on the command line. Note that
if no file operand is given, grep searches the working
directory. This is equivalent to the -d recurse option.
-l, --files-with-matches
Suppress normal output; instead print the name of each input
file from which output would normally have been printed. The
scanning will stop on the first match.
RuntimeError: Click will abort further execution because Python 3 was configured to use ASCII as encoding for the environment.
Consult https://click.palletsprojects.com/python3/ for mitigation steps.
RuntimeError: Click will abort further execution because Python 3 was configured to use ASCII as encoding for the environment.
Consult https://click.palletsprojects.com/python3/ for mitigation steps.
This system supports the C.UTF-8 locale which is recommended.
You might be able to resolve your issue by exporting the following environment variables:
export LC_ALL=C.UTF-8export LANG=C.UTF-8
In Python 3.7 and later you will no longer get a RuntimeError in many cases thanks to PEP 538 and PEP 540, which changed the default assumption in unconfigured environments.
NOTE: Most of the Linux distributions ship two open-vm-tools packages, "open-vm-tools" and "open-vm-tools-desktop". "open-vm-tools" is the core package without any dependencies on X libraries and "open-vm-tools-desktop" is an additional package with dependencies on "open-vm-tools" core package and X libraries.
$ perl -version
This is perl 5, version 26, subversion 1 (v5.26.1) built for x86_64-linux-gnu-thread-multi
(with 67 registered patches, see perl -V for more detail)
Copyright 1987-2017, Larry Wall
Perl may be copied only under the terms of either the Artistic License or the
GNU General Public License, which may be found in the Perl 5 source kit.
Complete documentation for Perl, including FAQ lists, should be found on
this system using "man perl" or "perldoc perl". If you have access to the
Internet, point your browser at http://www.perl.org/, the Perl Home Page.
$ sudo ./vmware-install.pl
[sudo] password for <user name>:
open-vm-tools packages are available from the OS vendor and VMware recommends
using open-vm-tools packages. See http://kb.vmware.com/kb/2073803 for more
information.
Do you still want to proceed with this installation? [no]