"The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits" の論文要約メモです。
はじめに
今回まとめる論文はこちら:
- 2024/02/27 公開
- Microsoftのチーム
- コード: unilm/bitnet at master · microsoft/unilm · GitHub
なお本記事で掲載する図は全て上記論文からの引用です。
The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
概要
- 背景
- 近年のLLMの発展は目を見張るものがあるが、そのモデルサイズの増加により必要なリソースも増加している
- こうした問題には、post-training quantizationをはじめとするアプローチが多数提唱されてきた
- BitNetのような1-bitモデルアーキテクチャは、大きな計算効率向上が見込めることが示された
- 乗算が不要
- 少ないメモリ使用量
- 課題
- BitNetより良いものを作る
- やったこと
- BitNet b1.58を作った
- {-1, 0, 1}の3値をとる
- ※ 1-bit BitNetは{-1, 1}の2値だった
- BitNet b1.58を作った
- 結果
- 一定サイズを超えると、非量子化モデルと同等あるいは上回るベンチマーク結果を示した
- 計算効率も優れていた
手法
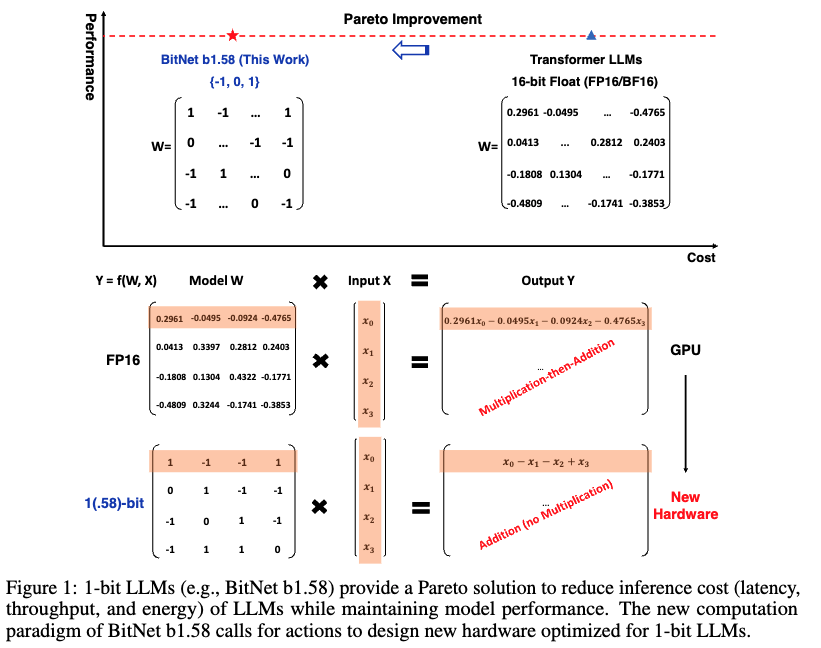
- BitNet b1.58は、BitNetアーキテクチャを基にする
- nn.LinearではなくBitLinearを使う
- 重みには1.58-bit: {-1, 0, 1} を使う
- Activationは8-bit
- 1.58-bit: {-1, 0, 1}の導き方
- 重みを絶対値平均でスケールした後、 {-1, 0, +1}に丸め込む
- コンポーネント構成はLLaMAに従う
結果

- Perplexityはサイズ3BでLLaMAに並び、サイズ3.9Bではかなり優れた結果を示した
- メモリ/レンテンシの面でもBitNet b1.58の方が優れていた

- モデルサイズが大きくなるにつれてBitNet b1.58とLLaMAの差は縮まり、サイズ3Bで横並び、サイズ3.9BではLLaMAを上回った
- 評価にはlm-evaluation-harnessを使用した
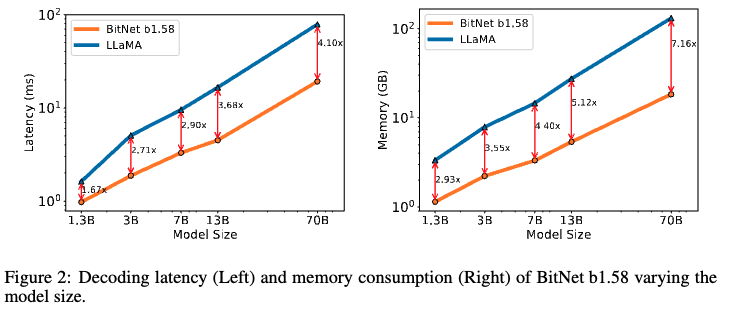
- モデルサイズが大きくなるにつれ、メモリ/レイテンシはLLaMA比較でより効率的になった

- エネルギー消費量はBitNet b1.58の方が圧倒的に少なかった

- BitNet b1.58の方が大きなバッチサイズ、高いスループットを示した

- より大きな学習データでの振る舞い/BitNet b1.58の学習トークン量でのスケーラビリティを検証
- 2T(trillion) tokenの学習データで、(同じデータで学習されたSOTAオープンソースモデルの) StableLM-3Bと比較
- BitNet b1.58の方が優れた結果を示した
おわりに/所感
以上、論文"The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits"の要約メモでした。
以下は私の個人的なメモです。
- 筆者たちは何を成し遂げようとしてるのか
- 量子化モデルが、性能面でも非量子化モデルに並びうることを示す
- アプローチの鍵となる要素は何か
- 重みを3値にした
- 次に読みたい引用論文は何か
- その他所感
- 学習時の処理がよくわからなかったので、BitNetの元論文とかBitLinearの実装とか眺めたい
- 量子化したのに性能が変わらない(むしろ上がることも)って面白い
- 確かに、このような情報伝達の形の方がより脳神経の発火に近そう
- どんどんAIが脳神経に近付いている気がして興奮する
[関連記事]
参考
[2402.17764] The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits