最初のGPT論文"Improving Language Understanding by Generative Pre-Training" の要約メモです。
はじめに
今回まとめる論文はこちら:
Improving Language Understanding by Generative Pre-Training
OpenAIによる初代GPT論文。
- 2018/05 公開
- OpenAI
- コード: GitHub - openai/finetune-transformer-lm: Code and model for the paper "Improving Language Understanding by Generative Pre-Training"
なお本記事で掲載する図は全て上記論文からの引用です。
The English translation of this post is here.
Improving Language Understanding by Generative Pre-Training
概要
- 背景
- 世の中にはラベルなしのテキストデータは大量にあるが、ラベルありの学習用データは限られた量しかない
- 課題
- 現状、用意が大変なラベルあり学習データへの依存度が高い
- ラベルなしテキストデータをいい感じに活用する方法がまだわかっていない
- やったこと
- ラベルなしテキストデータによる汎用事前学習(Generative Pre-Training)の後に、特定タスクに対応するためのラベルあり学習データによるfine-tuning、の二段構えによるモデル構築
- アーキテクチャはTransformerベース: Decoder部分のみ
- 結果
- 幅広い言語タスクで当時のSOTA達成
手法
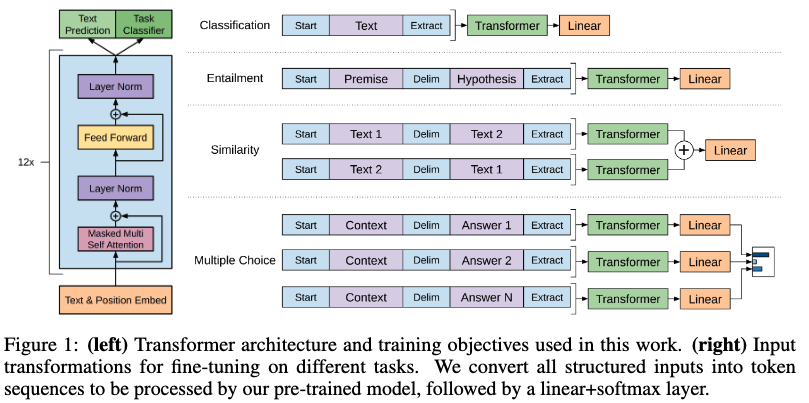
- Transformer decoderをベースにしたアーキテクチャ
- ラベルなしテキストデータでpre-training
- 教師ありfine tuningではTransformerにlinear+softmaxを追加
- 目的関数には、pre-trainingの目的関数を重みづけ加算したauxiliary objectiveを採用
- タスクに応じて、入力の形態をTransformerが処理できる一続きのtoken列に変換
- タスクに応じて、複数のTransformerを並列に組み合わせる
結果
Natural Language Inferenceタスク
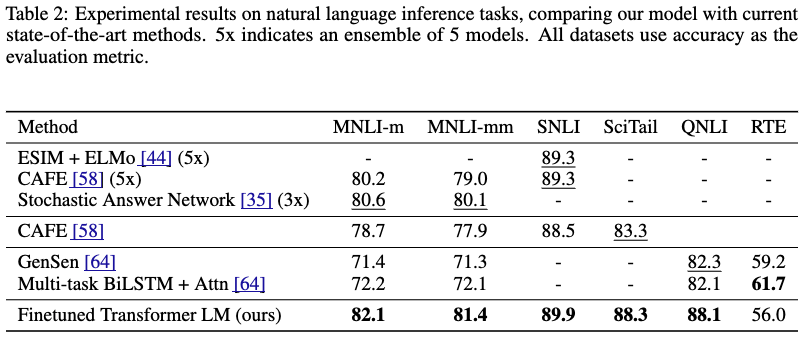
- テキストの論理包含認識タスク
- ふたつの文章について、包含、矛盾、中立のいずれかを判断する
- RTE以外で既存モデルを上回った
Question answering / commonsense reasoningタスク
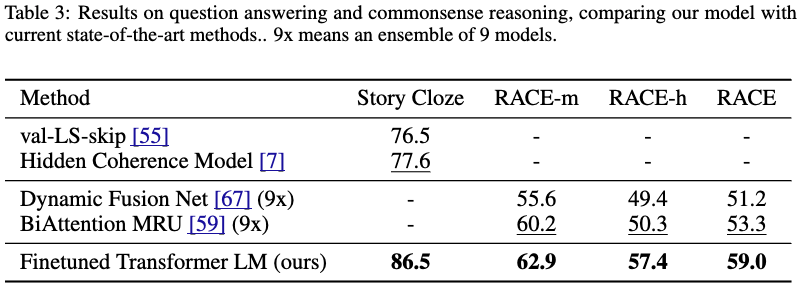
- RACE: 中学高校の英語(国語)の試験文章を元にしたQAタスク
- Story Cloze: ストーリーの正しい結末を選ぶタスク
- いずれも既存モデルを上回った
- 長コンテキストの文章を扱う能力を示している
Semantic Similarity / 分類タスク
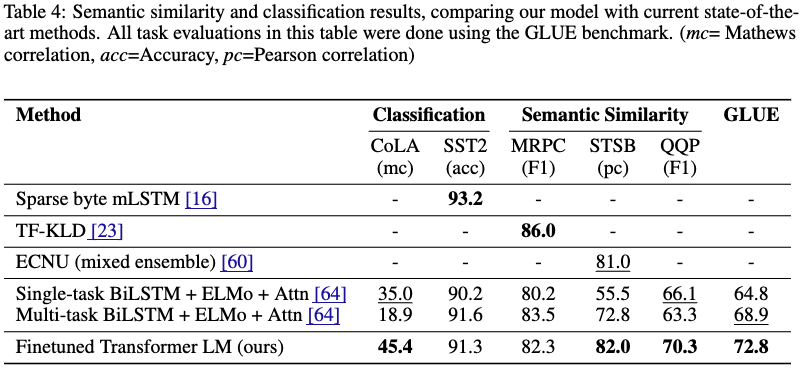
- Semantic Similarity: 二つの文が意味的に等価かを判断
- 3つのうち2つで既存を上回った
- Classification/テキスト分類
- CoLAで既存SOTAを大きく上回り、SST2で既存SOTAに近い結果を出した
分析
Pre-trainingは本当に意味があったのか?
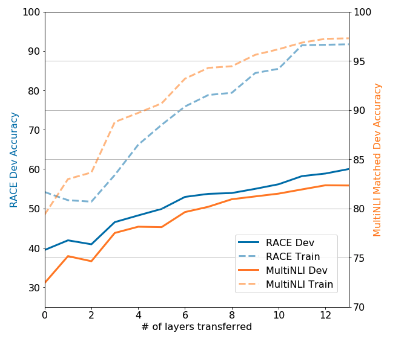
- 転移学習に使った事前学習layerが多ければ多いほど、タスク精度は高かった
- 事前学習で習得した知識がタスク実行に役立っている
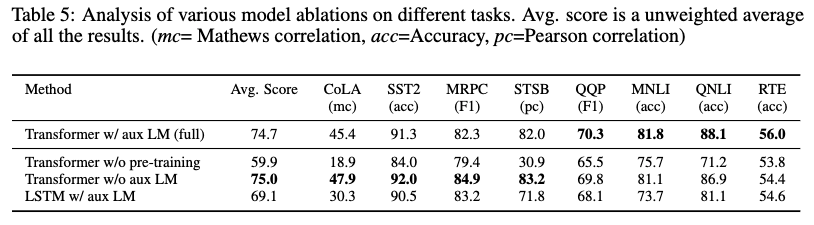
- Pre-trainintを行わないと、一貫して結果は悪化した
おわりに/所感
以上、論文"Improving Language Understanding by Generative Pre-Training"の要約メモでした。
以下は私の個人的なメモです。
- 筆者たちは何を成し遂げようとしてるのか
- ラベルなしテキストデータの有効活用方法の提示
- アプローチの鍵となる要素は何か
- ラベルなしテキストデータによる汎用事前学習を行なったのち、タスク特有のラベルあり学習データでfine-tuningを行う二段構成
- Transformer decoderアーキテクチャの採用
- 次に読みたい引用論文は何か
- Transformer decoderモデル [1801.10198] Generating Wikipedia by Summarizing Long Sequences
- その他所感
- ラベルなしテキストデータでの事前学習が有効なアプローチである、を示したこの発見と、この先発表されるScaling lowが合わさって、昨今のテキストデータによる大量学習の方向性が定まることになったんだろうか。 今までなんとなく固有名詞として見ていたGPT/Generative Pre-Trainingの意味も、ようやくこの論文を読んで腑に落ちた。
[関連記事]