GPT-2の論文"Language Models are Unsupervised Multitask Learners" の論文要約メモです。
はじめに
今回まとめる論文はこちら:
Language Models are Unsupervised Multitask Learners
- 2019/02 公開
- OpenAI
- コード: GitHub - openai/gpt-2: Code for the paper "Language Models are Unsupervised Multitask Learners"
GPT-2に関する論文です。
なお初代GPT論文はこちら:
※ 本記事で掲載する図は論文からの引用です。
The English translation of this post is here.
Language Models are Unsupervised Multitask Learners
概要
- 背景
- これまで自然言語処理タスクは、教師あり学習によって解かれてきた
- 課題
- これまでの言語モデルは、教師あり学習によるいわば特定領域のみの狭い専門家だった
- 幅広い領域のジェネラリストな言語モデルを作ることはできていなかった
- やったこと
- WebページのスクレイピングデータセットWebTextを作った
- 教師なし学習によるGPTモデルを構築した
- WebTextを利用
- ByteレベルをベースにしたBPEを利用
- アーキテクチャは初代GPTベースに微改変
- 最大モデル(1.5B)をGPT-2と呼ぶ
- 結果
- 文書理解タスクで、ラベルデータによる追加学習なしに既存モデルに匹敵する結果が出た
- 言語モデリングタスクでは、多くのデータセットでSOTA達成
- その他のタスクでもまあまあの結果だった
- モデルサイズが大きいほど結果がよかった
手法
学習データセットWebTextの作成
- WebText: RedditからリンクされたWebページをスクレイピングしてデータセットを作成

- 明示的な翻訳ペアをデータとして用意しなくても、Webページ内にこのような翻訳データがあるので、翻訳タスクにも対応できることを期待
BPE: Byte Pair Encoding
文字列をどうエンコーディングしてモデルへの入力とするか?
課題:
- Unicode文字列をUTF-8のbyte列として扱う従来の方法は、単語レベルのタスクで性能が出ない
- BPE: Byte Pair Encodingは、その名前に反してUnicodeのbyte列ではなくコードポイントに対して行われている
- Unicodeコードポイントに対してBPEする場合、必要な語彙は膨大になってしまう
- Byteレベルを対象にしたBPEなら、必要な語彙は少なく抑えられる(256個)
- しかし、BPEを直接byteレベルに適用しても、最適化は上手くいかない
- 頻出単語と句読点の組み合わせが単語としてまとめられてしまったりする
で、どうしたのか:
- ByteレベルのBPE
- ただし、異なるカテゴリ間の結合は排除
これによって、byteレベルアプローチの汎用性を持たせたまま、単語レベルアプローチの性能を目指す。
モデルアーキテクチャ
初代GPTのアーキテクチャをベースにしながら少し変更:
- Layer normalizationを、各Transformerサブブロックの入力に対して行うよう移動
- 最後のself-attentionブロックの後にLayer normalizationを追加
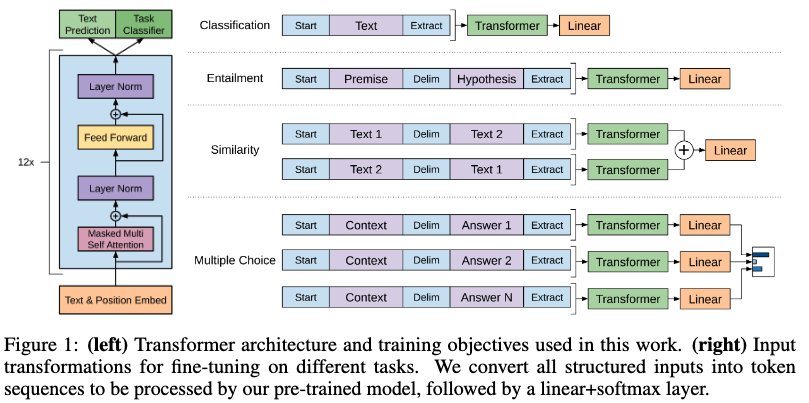
また、複数サイズのモデルを作成。 最大サイズのものをGPT-2と呼ぶ。

結果
言語モデリングタスク

- 8つのデータセットのうち7つでSOTA
- 小さなデータセットでより大きな改善が見られた
- WikiText2, PTB
- 長距離依存のデータセットでも大きな改善が見られた
- LAMBADA, CBT
- 1BW (One Billion Word Benchmark)の結果は悪かった

- モデルサイズが大きいほど良い結果になった
常識的推論能力
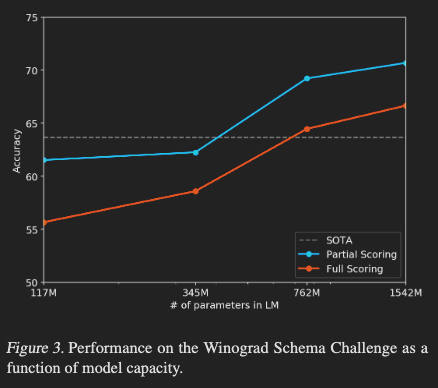
- Winograd Schema Challenge: 文章のあいまいさを解消する能力から常識的推論力を測定する
- SOTAを達成
文章読解力
Conversation Question Answering (CoQA)でテスト。
- 55 F1スコアを達成
- ベースラインの3/4に匹敵または上回る結果
- QAペアのラベルによる追加学習なしで
- SOTAはBERTベースのモデルで、人間に近い89 F1スコア
要約タスク

- 既存モデルよりもあまり優れない結果
- 直近の内容にフォーカスしてしまったり、詳細部分をちゃんと分かってなかったりする
翻訳タスク
| タスクセット | GPT-2の結果 |
|---|---|
| WMT-14 English-French | 5 BLEU |
| WMT-14 French-English | 11.5 BLEU |
- WMT-14 English-Frenchの結果は、既存の教師なしモデルより少し低い
- WMT-14 French-Englishの結果は、多くの教師なしベースラインよりも良いが教師なしSOTAよりは低い
QAタスク
事実を回答するスタイルのタスクにどのくらい答えられるか?
- データセット: Natural Questions
- GPT-2の正答率: 4.1% (exact match評価)
- 最小モデルの結果(1%以下)に比べると良い結果なので、モデルサイズを上げていけば良くなるかもね
- Retrievalを組み合わせた既存QAシステムは30-50%
- GPT-2の方がずっと低い結果
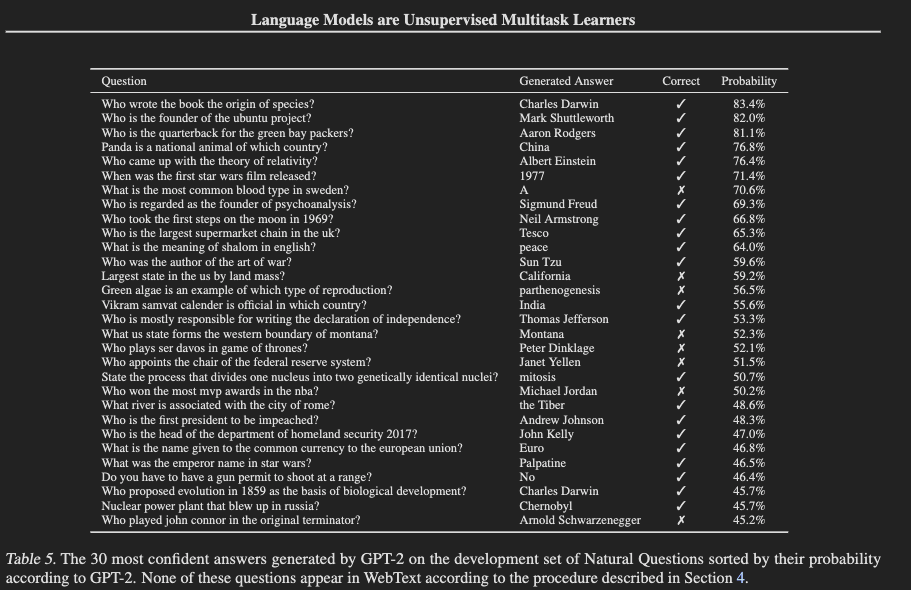
Generalization vs Memorization
これらの結果は、本当にGPT-2のGeneralization/汎化能力によるものなのか?
学習データセットとテストデータセットが被っていて、Memorization/思い出しによって解いてるのではないか?
WebTextは雑多にWebページを大量に取ってきてるわけだし。。
の懸念について検証。

- 学習データ(WebText)と各テストデータセットについて、8グラムのBloomフィルターで重複度合いを検証
- WebTextの重複は1-6%ほど
- 平均3.2%
- 各テストデータセットそのものの学習データは平均5.9%の重複
- むしろWebTextの方が重複が少なかった
おわりに/所感
以上、論文"Language Models are Unsupervised Multitask Learners"の要約メモでした。
以下は私の個人的なメモです。
- 筆者たちは何を成し遂げようとしてるのか
- 教師なし学習/zero-shotによるモデルの汎用的な言語能力を示したい
- アプローチの鍵となる要素は何か
- 高クオリティのwebスクレイピングデータWebTextの作成
- モデルサイズを大きくして、教師なし学習
- ByteレベルBPE
- 次に読みたい引用論文は何か
- 所感
- 初代GPTがfine-tuningベースだったのに対して、GPT-2ではfine-tuningなしの教師なし学習での能力を示している。 この後のscaling lowと合わせて、モデルをデカくすればまずは上手くいく、の世界に入っていったのがうかがえて面白い。
[関連記事]