LLMOpsとは何か? 概念の勘所をまとめます。
はじめに
LLMアプリケーションを作る時は、LLMそのものの知識の他に、いかにプロダクトとして良いものにしていくかというアーキテクチャ的観点、あるいはDevOps的視点が大切です。
これまでも、個人的にいくつかLLMアーキテクチャやLLM品質評価テストに関する記事を書いてきました。
- LLMアプリケーションアーキテクチャ入門 - BioErrorLog Tech Blog
- LLMの回答を自動評価するOpenAIプラクティス - BioErrorLog Tech Blog
- LangCheckでLLMの回答を自動評価する - BioErrorLog Tech Blog
そんな中、LLMOpsというキーワードを見かけました。 一言で言わんとする概念がなんとなく伝わる、良い単語に思います。
今回はこのLLMOpsという概念を広めるべく、ポイントを整理しようと思います。
主に下記Josh Tobin氏のLLMOpsに関する発表を元に、LLMOpsの要点をまとめます。 (スライドデータはこちら)
補足: LLMOpsの指す範囲について
LLMOpsという単語の指し示す範囲は、使い方によって解釈に幅があります。
例えばFoundation ModelそのもののOpsについて指す場合もありますし、LLMモデルを活用したアプリケーションについて指す場合もあります。
本記事では、Foundation Modelそのものについてではなく、LLMを活用したアプリケーションに関する範囲としてのLLMOpsに言及します。

LLMOps
モデルの選定

採用するLLMモデルの選定は、下記トレードオフを元に考えます。
- Quality: モデルそのままの状態で対象タスクを解く品質
- Speed: モデルレスポンスの速度/遅延具合
- Cost: モデル利用料金
- Extensibility: Fine-tuning可能か?などの拡張性
- Security: データセキュリティおよびライセンス
現状、多くのユースケースではGPT-4から始めることが推奨です。

OSSモデルを使うべきか、プロプライエタリモデルを使うべきか?
プロプライエタリモデルは、下記の点でメリットがあります。
- 高品質
- ライセンスの問題が少ない (OSSモデルはライセンス上利用範囲が制限されることも多い)
- モデルを稼働させるインフラを考慮する必要がない (OSSモデルを使う時はインフラ管理を考える必要がある)
一方OSSモデルの嬉しさは、
- カスタマイズしやすい
- データセキュリティを確保できる
にあると言えます。
モデルの進歩は日進月歩です。 LLMモデルを取り巻く状況は常に変化していくので、その時々に合わせてそれぞれのメリット/デメリットからモデル選定の判断材料にしましょう。

あなたのユースケースでどのモデルが最もよく機能するのか、を知るためには、対象ユースケースに対するパフォーマンスを直接評価するほかありません。 (これについては、後述の"テスト/品質評価"の章で詳しく解説します)
ベンチマーク指標は参考にはなりますが、それをもって対象タスクへの性能を推し量るのは危険です。
プロンプト管理
LLMモデルを選定したら、次はプロンプトエンジニアリングに取り組みます。
プロンプトを書いて変更して...というループを繰り返す中で、どうやってその作業の履歴を記録すればよいでしょうか。

この課題感は、かつて"従来の"深層学習における実験管理の課題と似ています。
かつて深層学習では、モデル学習時にそのパイパーパラメータをスプレッドシートなどにメモし、ローカルPCに保存することでモデル学習のログを残していました。 しかし、このやり方では、再現性は担保できず、チームと結果を共有することもできません。
ここに、実験管理の方法論が生まれました。
model.train()を実行する度に実行条件と結果のログが自動で保存されるようになり、このログは再現可能かつ共有も容易です。
そこで現在のプロンプトエンジニアリングを考えてみましょう。 プロンプトを変更し、その結果を実行しますが、古いプロンプトはともすれば失われてしまいます。 過去の結果を再現する方法も、チームと共有する形式も、まだ確立されていません。

そこでプロンプト管理の方法を考えてみましょう。 3つのレベルがあります。
- レベル1: 何もしない
- レベル2: プロンプトをgit管理する
- レベル3: 専用ツールでプロンプト管理する
レベル1"何もしない"は、叩き台v0を作る段階では十分でしょう。 しかしアプリケーションを実際に構築するフェーズでは不十分です。
レベル2"プロンプトをgit管理する"は、現時点では多くのユースケースで最適な方法です。 基本はgit管理をデファクトと捉えるのが良いでしょう。
レベル3"専用ツールでプロンプト管理する"は、複数のモデル評価を並行で走らせるようになったり、プロンプト変更をgit管理やデプロイから独立して管理したくなったり、技術に詳しくないステークホルダが関与する場合には選択肢に上がるでしょう。 プロンプト管理ツールはまだまだ発展途上の領域ですので、今後も動向をウォッチしておくことをお勧めします。
テスト/品質評価
LLMアプリを開発/運用する際の重要な問題があります:
「どのようにして、プロンプトの変更あるいはモデルの変更の影響を測定するのか?」
例えばプロンプトを変更した際、手元にあるいくつかの質問例に対しては結果が改善しているように見えても、プロダクトが対応すべき質問群全体に対して結果が改善しているとは限りません。
プロダクションにおけるLLM回答全体の品質を高めていくには、回答品質を測定/保証するテストの仕組みを構築する必要があります。

LLMテストの設計には、2つの軸があります。
- どんなデータを使うのか
- どんなメトリクスを使うのか
まずはLLMテストに使うデータについて議論しましょう。
観点は4つです。
- 段階的に始める
- LLMを活用する
- 運用しながらテストを追加する
- テストカバレッジを考慮する
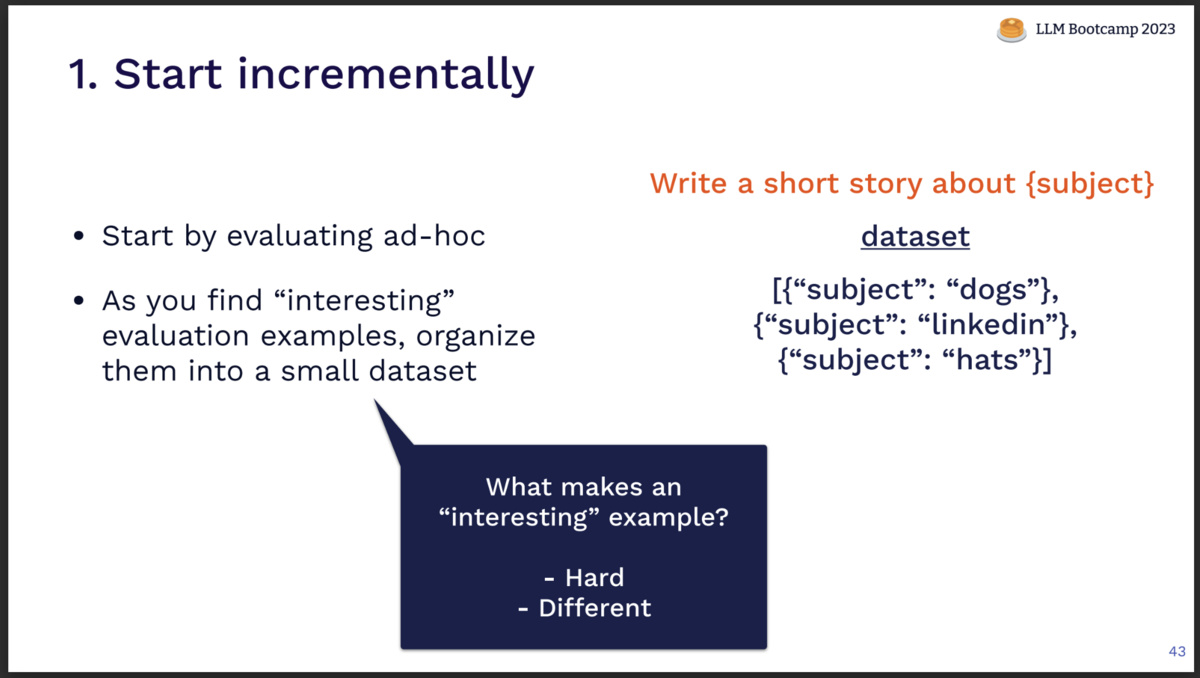
「段階的に始める」
テストデータは一気に用意するのではなく、小さくアドホックなテストケースから初め、徐々に成熟させていくようにします。
特に、下記のような上手くいかないケースを重点的にテストとして追加していきます。
- Hard: 回答が難しく、間違った回答が出力されてしまうケース
- Different: ユーザー(あるいはあなた)の想定とは違った回答が出力されてしまうケース
上手くいかないケースをテストに追加し、その回答を改善し以後保証していくことで、回答全体の底上げをしていきます。
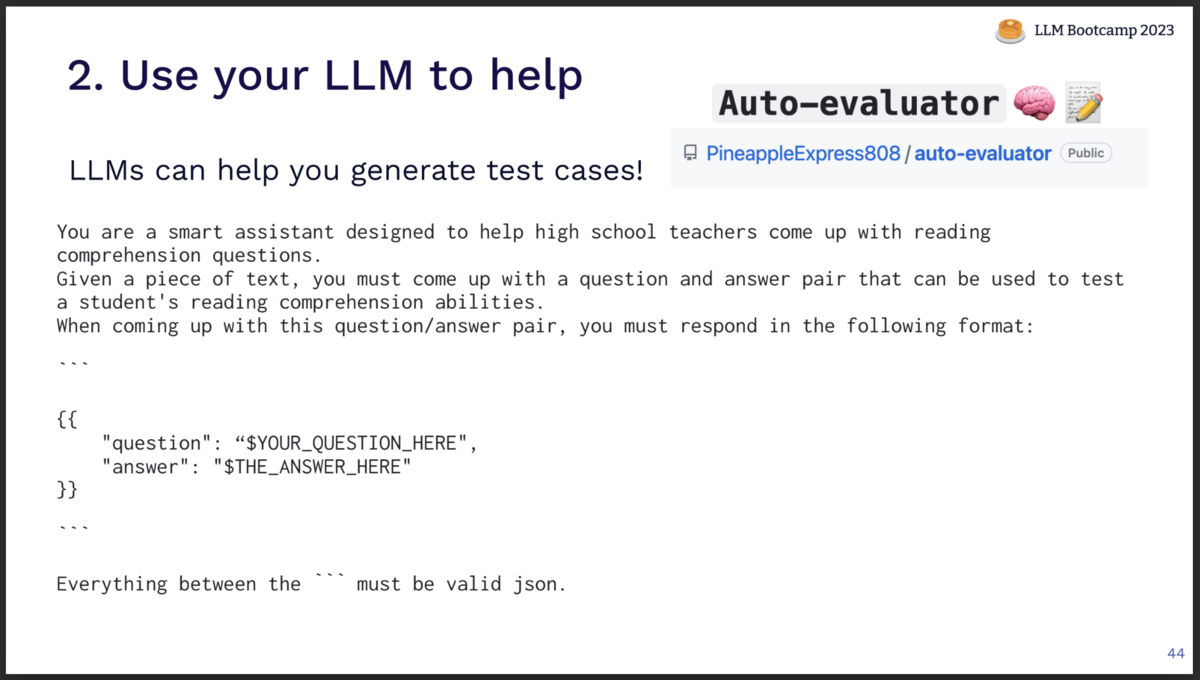
「LLMを活用する」
テストケースとするQAのペアを用意するのは手間がかかります。 この作業をLLMにやらせるのも有効な選択肢です。
例えばスライドに示したプロンプトのようにして、与えたドキュメントの読解力を試すQAを生成させるようなやり方があります。
また、Auto-evaluatorのようなツールを使ってQAペアを生成させることもできます。

「運用しながらテストを追加する」
運用が始まってこそ、データを追加してテストを成熟させていきます。
- ユーザーがBad評価したケース
- アノテーターが気に入らなかったケース
- 別のLLMモデルが低評価したケース
- 現在のテストケースではカバーできてない外れ値的なケース
- それまで重視してなかった部分のデータ
これら発見しては順次テストケースに追加していくことで、回答性能を底上げしていくことができます。

「テストカバレッジを考慮する」
用意したテストケースが、実際のプロダクションでユーザーが入力しうるデータ範囲をカバーしているのが、カバレッジ範囲としては理想です。
さらには、より難しい入力、テストすべきケースを重点的にカバーできていればなお良いでしょう。 また評価メトリクスが、テストとプロダクション(ユーザー)で乖離していないことも重要です。
実際のユーザーの体験に合ったメトリクスで、プロダクションで有り得るデータ範囲を、困難なケースでより重点的にテストするようにしましょう。
次は、評価メトリクスについて見ていきます。

評価メトリクスの例を挙げます。
- 従来の機械学習と同様の評価メトリクス
- 出力ラベル正誤による精度
- リファレンス比較メトリクス
- 理想回答と実際の回答の一致度を測定する
- Semantic similarity検定
- LLMモデルを使って"これら二つの回答は事実上一致しているか"を判定する
- "Which is better" メトリクス
- 過去バージョンの解答に対して、新バージョンの回答が優れている/劣っているのかをLLMに判定させる
- フィードバック反映テスト
- 過去の回答に対して人間からフィードバックがあった場合、新バージョンの回答がそのフィードバックを反映したものであるかを、LLMに判定させる
- 静的メトリクス
- 外部情報なしでできるテスト
- 出力フォーマットの検証 (例: JSONフォーマットかを検証)
- LLMに解答の品質をグレード評価させる (例: 1-5で回答品質をスコアリングさせる)
では、どのメトリクスを採用すべきか? 考え方の例がこちらです。
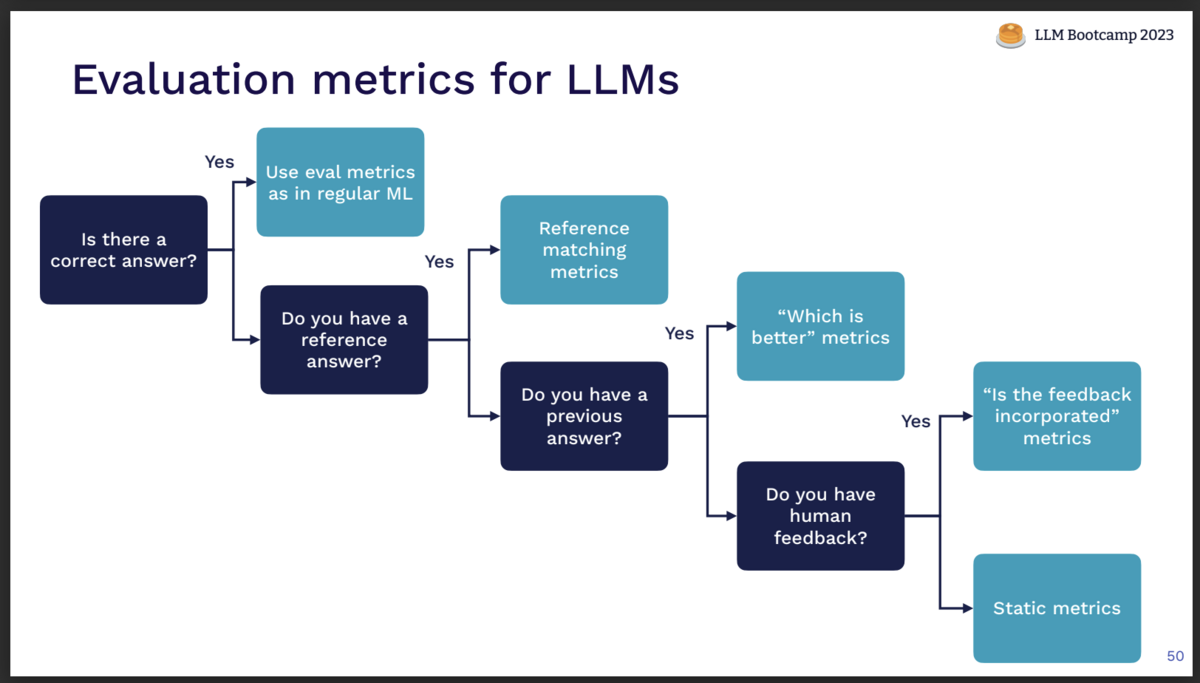
正答が存在するのであれば、従来の機械学習同様、出力の正誤を判定します。
リファレンスとすべき理想回答を用意できるのであれば、リファレンス比較メトリクスを使いましょう。
過去の回答を参照できるのであれば、"Which is better" メトリクスも有効です。
人間によるフィードバック情報があれば、フィードバック反映テストが使えます。
上記のいずれも適用できなくとも、静的メトリクスでのテストが可能です。

最後にテストの自動化についても議論します。
テスト評価にLLMを活用することで、多くの判定を自動化することが可能でしょう。 テストを自動化できると、テストを並列実行して、チューニングの試行錯誤をいくつか同時に行うことも可能です。
しかし、多くのケースでテスト実行の全てを完全に自動化することは難しいです。 テストにおける評価にLLMを使っている場合は、そのテスト用LLM自身の出力も完全に信頼することはできません。
手動確認が必要になる箇所が残ることも受け入れつつ、自動化を進めていきましょう。
デプロイ

LLMをAPI経由で利用する場合は、そのロジックやプロンプト、プロンプトチェーンをデプロイすることになります。 アーキテクチャとして、LLMを呼び出すロジックを独立のサービスとして設計することも選択肢に入るでしょう。
またOSSのLLMモデルを利用している場合、そのデプロイはさらに複雑です。 ここでは詳細を割愛しますが、下記のリソースが参考になります。

また、デプロイされたプロダクションのLLM出力を改善する工夫もあります。
- 自己批評
- LLMが一度出した出力に対し、"これは正しい回答か?"と再度LLMモデルに問う
- Guardrails AIというOSSツールも選択肢になる
- 多くの回答候補を出力させ、その中から最善の回答を選ばせる
- 多くの回答候補を出力させ、その組み合わせから最終回答を生成する
これらの工夫は精度を上げるには有効ですが、もちろん追加のオーバーヘッドがかかります。 トレードオフを考慮しながら、採用を検討しましょう。
モニタリング

モニタリングの基本的な考え方としては、まずはLLM回答の成果、つまりLLM出力がユーザーの課題を解決できたのかどうかの観測を目指します。
ユーザーのフィードバックを取得したり、それが難しければ別の代替メトリクスを観測します。 逆に、何が上手く行ってないのかを測定することでもユーザーの満足度を測ることが可能です。
また可能であれば、レイテンシをはじめとするモデルパフォーマンスも取得すると役に立ちます。

ユーザーフィードバックの収集は、LLMアプリのモニタリングの中でも特に重要です。
ユーザーにとって負担が少なく、かつ高い情報量を持つフィードバックを設計しましょう。 ユーザーのワークフローそのものからフィードバック情報を得ることができれば理想です。
ユーザーフィードバック取得パターン例:
- “Accept changes”パターン: ユーザーがLLMの提示した変更を受け入れたかどうかを収集する
- “Thumbs up / down”パターン: ユーザーがLLMの出力を気に入ったか気に入らなかったをGood/Badボタンから収集する
- 長文フィードバック: 文章によるフィードバックの要求が可能なら、数は少なくとも豊富な情報量が得られる

では実際のLLMアプリではどのような問題が起きうるのでしょうか?
最もよくあるユーザーの不満は、UIに関するものです。 特に、レスポンス速度に関する不満が一番よく見られます。 遅延を削減するのはなかなか難しい問題ですが、状況に応じて対処しましょう。
その他にも、下記のような問題が起こり得ます:
- 間違った回答 / ハルシネーション
- 長く冗長な回答
- 明言を避ける回答 (例:「私はAIですので、XXに関する回答はできませんが...」)
- プロンプトインジェクション
- 害悪性の高い回答
これらの現象をモニタリングし、手を打っていくことが重要です。
継続的改善とfine-tuning

運用の中で得られるユーザーフィードバックは、継続的にプロダクトを改善するためには不可欠です。
ユーザーフィードバックは、主に二つの使い道があります。
- プロンプトの改善に繋げる
- LLMモデルをfine-tuningする

多くの場合、プロンプトチューニングが継続的改善の主軸です。
ユーザーフィードバックから現状のLLMアプリがカバーできていない領域を見つけ、重点的に改善していきます。 プロンプトエンジニアリングや、in-contextに含めるデータの改善が有効です。
これらは主に人間の手によって行うことが多いですが、このプロセス自体をLLMによって自動化するというのも良いチャレンジになるでしょう。

現状、特にGPT-4のような大型モデルを使っている場合は、fine-tuningでその手間に見合うメリットが得られるケースは限られています。 まずはプロンプトエンジニアリングやin-context learningの見直しから取り組むことをお勧めします。
それでも、下記のような理由がある場合はfine-tuningを選択肢として検討すると良いでしょう。
- 小さなモデルを使う必要がある場合
- 大量のデータがあり、かつin-context learningがうまく機能していない場合
結論: LLMアプリケーションのテスト駆動開発
LLMアプリケーション開発は未だ新しい分野であり確立されたベストプラクティスはありませんが、最後に一つの型としての開発フローをまとめます。
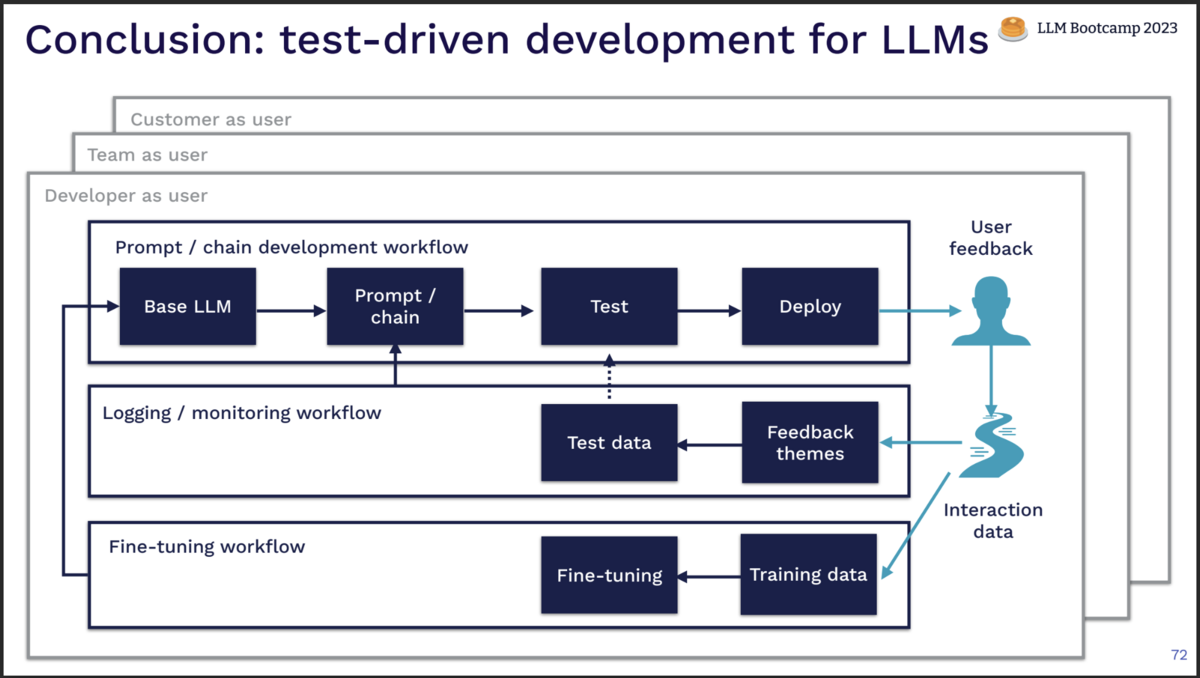
プロダクト開発のスタート時点から、流れを辿ってみましょう。
まずはベースとなるLLMモデルを選定し、プロンプトを実装します。 アドホックに小さなテストケースを用意してある程度の性能を保証したら、デプロイしましょう。 この最初の段階でのエンドユーザーは、あなた一人、開発者自身のみです。
ログ/モニタリングからユーザーフィードバックを確認し、改善点を洗い出します。 改修に取り組むときはテストを作成し、全体としての品質担保を積み上げていきます。 テストデータは、ユーザーフィードバックやログから抽出するのも有効です。
LLMアプリ性能への要求が複雑性を増した時は、fine-tuningも選択肢に上がります。 ユーザーの利用ログから学習データを確保できるか、検討しましょう。
これら、テストの作成 -> プロンプトエンジニアリング -> ユーザーフィードバック からなるループを、エンドユーザーの範囲を拡大させながら繰り返します。
- 開発者ひとりをエンドユーザーとする
- 開発チームをエンドユーザーとする
- 実際のエンドユーザーに開放する
このようにユーザーフィードバックとテストによるループを繰り返しながら、LLMアプリ全体の性能を向上させていきましょう。
おわりに
LLMアプリの開発は、AI知識だけではなくDevOps的な観点、アーキテクチャ的な観点も重要です。
本記事が参考にした発表ではLLMOpsの勘所がよく整理されていて、個人的にふわっと感じていた部分も明確に言語化されていて非常に勉強になりました。
以上、どなたかの参考になれば幸いです。
[関連記事]
参考
LLMOps (LLM Bootcamp) - YouTube
2023-llmbc-llmops.pdf - Google ドライブ
https://twitter.com/josh_tobin_
FMOps/LLMOps: Operationalize generative AI and differences with MLOps | AWS Machine Learning Blog
GitHub - rlancemartin/auto-evaluator: Evaluation tool for LLM QA chains
GitHub - guardrails-ai/guardrails: Adding guardrails to large language models.