Transformerの原典である"Attention Is All You Need" の論文要約メモです。
はじめに
かの有名なAttention Is All You Need、原典をちゃんと読んだことなかったので読みます。
- 2017/06/12にv1公開
- Google Brain / Google Research
- コード: tensor2tensor/tensor2tensor/models/transformer.py at master · tensorflow/tensor2tensor · GitHub
なお本記事で掲載する図は全て上記論文からの引用です。
Attention Is All You Need
概要
- 背景
- これまでシーケンス変換モデルは、RNNやCNNを含むencoder-decoderアーキテクチャが使われてきた
- Attentionも一部使われてきた
- 課題
- 並列処理できないので学習が大変
- やったこと
- RNNやCNNを使わず、Attentionのみを使ったモデルを作った
- 学習が並列実行可能
- その名もTransformer
- RNNやCNNを使わず、Attentionのみを使ったモデルを作った
- 結果
- 翻訳タスクでSOTA
- 英語構文解析でも良い結果を出した
- 汎化性能も高い
手法
モデルアーキテクチャ

- Encoder
- Layer数 N = 6
- Norm: Layer normalization
- Decoder
- Layer数 N = 6
- Musked Multi-Head Attentionのmaskingは、positionとしてそれ以前のtokenのみをattentionの対象とするためのもの
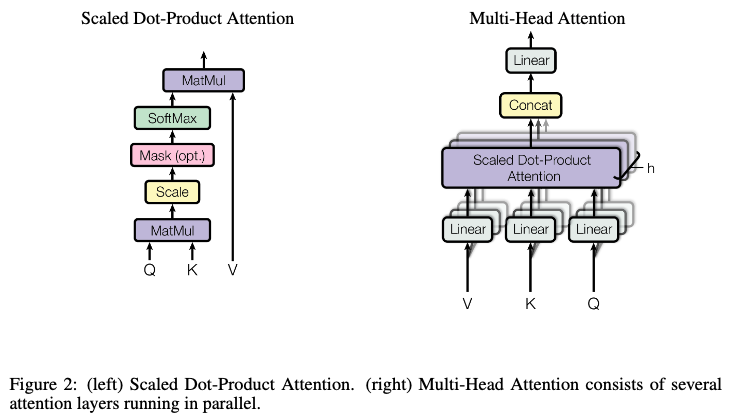
- Additive attentionではなくscaled dot-product attentionを使ったのは、計算効率面でメリットがあるから
- 理論的な計算量は両者で変わらないが、実際のところメモリ効率が良かったり最適化された行列乗算を使えたりする
- Keyの次元が大きくなるとdot-productの結果が大きくなってしまうので、スケーリングする
- Multi-Head Attentionのlayer数 h = 8
学習方法
- 8つのNVIDIA p100 GPUを使用
- Baseモデルの学習に12時間
- Bigモデルの学習に3.5日
- Optimizer
- Adam optimizer
- Regularization
- Resifual Dropout
- Label Smoothing
結果
翻訳タスク
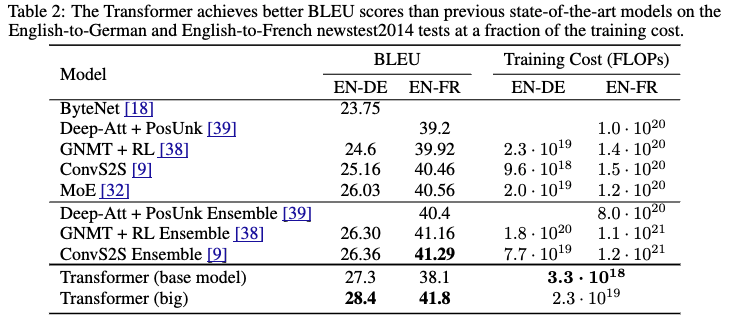
- Transformer (big)が英語-ドイツ語翻訳、英語-フランス語翻訳タスクで共に既存モデルを上回った
- Trandformer (base)でも英語-ドイツ語翻訳タスクでは既存モデルを上回った
- 学習コストは既存モデルより少ない
Transformerモデルバリエーション
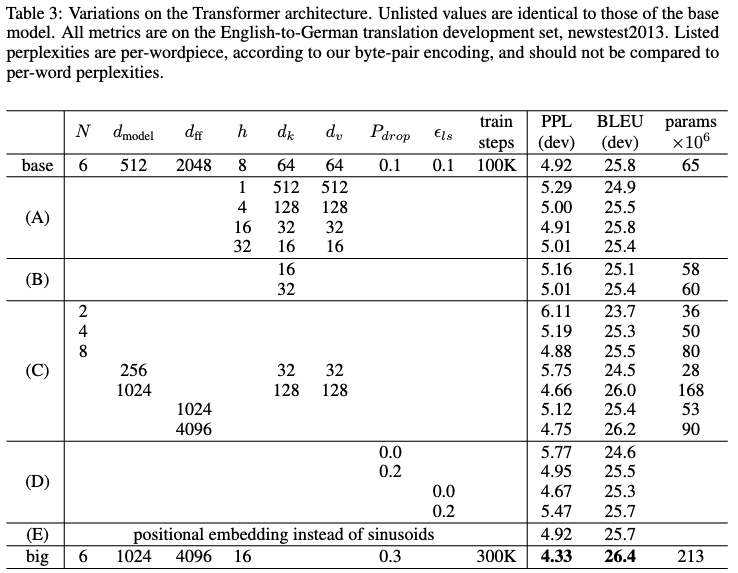
- (A): Attention headの値を変動
- Single-headだと結果(PPL, BLUE)は悪かった
- (B): Attention Keyのサイズ(次元)を減らす
- 性能が下がった
- (C): 大きなモデルほど性能が良かった
- (D): Dropoutを無くすと性能が下がった
- (E): Positional encodingをlearned positional embeddingにしても、結果はほぼ変わらなかった
英語構文解析
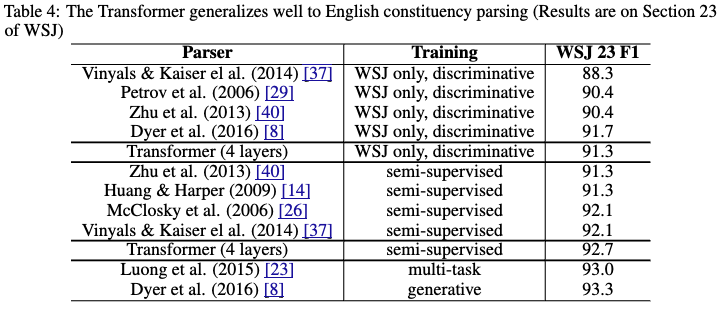
- Trandformerの汎化性能を検証するための実験
- このタスクに最適化させるチューニングは行なっていない
- Transformerモデルが多くの既存モデルを上回った
おわりに/所感
以上、論文"Attention Is All You Need"の要約メモでした。
以下は私の個人的なメモです。
- 筆者たちは何を成し遂げようとしてるのか
- 学習の並列処理が可能かつ高性能なモデルアーキテクチャの提唱
- アプローチの鍵となる要素は何か
- RNNもCNNも使わず、Attentionのみを使用
- Multi-Head Attentionの採用
- 次に読みたい引用論文は何か
- その他所感
- あの有名なTransformerアーキテクチャの図しか知らなかったので、どの部分が新規の概念なのかを知らなかった。 基本的にはRNNもCNNも使わずにAttentionのみを使ったのが鍵で、それ以外のアーキテクチャは既出の概念。 "Attention Is All You Need"というタイトルの主張もようやく腑に落ちる。
[関連記事]
参考
[1706.03762] Attention Is All You Need
tensor2tensor/tensor2tensor/models/transformer.py at master · tensorflow/tensor2tensor · GitHub