LLMアプリケーションにおけるアーキテクチャ構成の考え方を学びます。
はじめに
ChatGPTをはじめとするLLMの登場により、私の生活はすっかり変わりました。 一方で、LLMを組み込んだアプリケーションというものは、まだそこまで一般的ではありません。
GitHubが下記のブログの中で、LLMアプリケーションアーキテクチャの勘所を整理していました。
The architecture of today's LLM applications - The GitHub Blog
GitHubといえば、LLMアプリケーションの代表とも言えるGitHub Copilotを開発していますね。 今回はこの記事を参考にしながら、LLMアプリケーションアーキテクチャの要点を整理します。
※ 本記事で掲載する画像は上記記事からの引用です。
LLMアプリケーションアーキテクチャ入門
LLMアプリケーション構築の5ステップ

LLMアプリケーション構築を、5つのステップに分けて考えます。
- 解決すべき1つの課題を明確にする
- LLMモデルを選定する
- LLMモデルをカスタマイズする
- アプリケーションアーキテクチャを構築する
- アプリケーションの実行とオンライン評価
1. 解決すべき1つの課題を明確にする
LLMアプリケーションを設計する際には、1つの解くべき課題を設定することが重要です。 取り組む課題を集中させ、素早くイテレーションし、かつユーザーを喜ばすことのできる課題を設定します。
例えばGitHub Copilotでは、あらゆる開発者の課題をターゲットとするのではなく、IDEにおけるコーディング機能に集中して開発されています。
2. LLMモデルを選定する
自前でLLMモデルを構築/学習させる代わりに、すでに世にあるLLMモデルを採用することで、時間とコストを節約することができます。
ではどのようにしてLLMモデルを選定するべきでしょうか? いくつかの観点があります:
- ライセンス:
用途にあったライセンスを持っているモデルを選定します。例えば、商用アプリケーションを構築する場合、モデルも商用利用を許可している必要があります。 - モデルサイズ:
LLMモデルサイズは、パラメータ数7~175Bまで様々です。 一般的な経験則として、より大きいモデルほど性能が高く、一方小さなモデルの方が早くて安い傾向があります。 (もちろん、一概にそう断定できるものではありませんが) - モデルパフォーマンス:
Fine-tuningやin-context learningなどのカスタマイズをする前に、LLMに解かせたい課題に対して素の状態でどのくらい良い回答が得られるのか、も重要です。 オフライン評価でもモデルパフォーマンスを測ることができます。
3. LLMモデルをカスタマイズする
既存/pre-trainedのLLMをカスタマイズするには、主に以下の3つの方法があります。
- In-context learning:
In-context learningでは、モデルそのものは変更せず、プロンプト部分で情報を与えることによって振る舞いをカスタマイズします。 プロンプトで指示を与えたり、理想の解答を例示したり、追加の独自情報を与えたりなどなど、多様な方法でモデルの振る舞いをカスタマイズできます。 - RLHF (reinforcement learning from human feedback):
RLHFは、モデルの出力に人間のフィードバックを反映させるプロセスです。 例えばモデルの出力に対してユーザーが受け入れor拒否を選択し、その結果を報酬モデルとしてLLMモデルに反映させます。 - Fine-tuning:
Fine-tuningは事前学習済みモデルに対して再調整をかける方法です。 望ましい出力がラベル付けされたセットを用意してfine-tuningさせることにより、特定タスクや特定スタイルに特化したモデルを作れます。 ただ学習データの用意が必要なので、その点の労力/時間がかかる点に注意です。
4. アプリケーションアーキテクチャを構築する
LLMアプリケーションは、ざっくり3つの要素に分けて考えられます。
- ユーザーインプット:
UIやLLMモデル、アプリケーションをホストする基盤を設計します。 - インプット処理とプロンプト構築:
ユーザーインプットを受けてからLLMを呼び出すまでの情報処理を行います。 例: データソースの用意、データのembedding、ベクトルDB、プロンプト構築/最適化、データフィルターなど。 - AI呼び出しの効率化とセキュリティ担保:
LLMキャッシュ、LLMコンテンツフィルター/分類、LLMアプリ出力評価システムなどを活用して、LLMを効果的に利用します。
詳しくは後述のアーキテクチャ例で見ていきます。
5. アプリケーションの実行とオンライン評価
実際にアプリを実行する中でのユーザーからのフィードバックをもとに、LLMの性能を評価します (オンライン評価/online evaluation)。
例えばGitHub Copilotでは、ユーザーの受け入れ率 (ユーザーが提示されたコードをどれくらいの頻度で受け入れるか)や、保持率 (ユーザーが提示されたコードをどれくらいの頻度でどの程度編集するか) が測定されます。
アーキテクチャ例と構成要素
Wi-Fiに関するお問い合わせチャットボットを題材に、アーキテクチャ例を見ていきます。
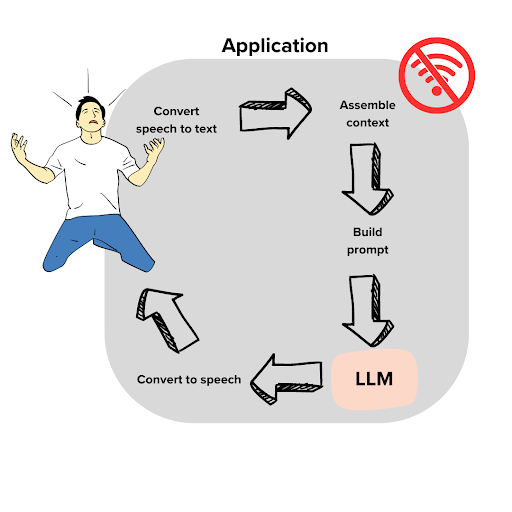

ユーザーインプット
例えば次のように、ユーザーが音声で問い合わせてくる場面を想像しましょう。
「テレビはWi-Fiに繋がっていたんだけど、カウンターにぶつけてWi-Fiボックスが落ちてしまったんだ!これでは試合が見れないよ。。」
さて、アプリケーションとしては何が必要でしょうか?
- LLM APIとアプリケーションのホスト:
LLM APIを備えたアプリケーションが稼働している必要があります。 実際にプロダクトを稼働させるときは、多くの場合クラウド上で構築することになるでしょう。 もちろんちょっとした検証であれば、ローカル端末上でやってみるのもありです。 - UI:
ユーザーが問い合わせに使うUIを用意します。 今回のようなケースでは、緊急問い合わせ用の動線を用意するのも良いでしょう。 - Speech-to-text 変換:
音声での問い合わせを受けるのであれば、音声をテキストに変換する処理も必要です。
インプット処理とプロンプト構築
問い合わせのテキストを元に文脈にあった回答をLLM生成させるには、以下のような構成要素が有用です。
- ベクトルDB:
Embedding/埋め込みを用いて追加の知識を格納します。 LLMが解答を生成する際、関連する情報をベクトルDBに問い合わせ、得た情報を用いて回答を生成させるようにすれば、独自のデータを元に回答させることが可能です。 - データフィルター:
データフィルターによって、LLMが個人情報などの許可されていないデータを処理することのないようにします。 amoffat/HeimdaLLMなどの実験的プロジェクトが参考になるかもしれません。 - プロンプト最適化:
ユーザーの質問をトリガーとし、実際にLLMに与えるプロンプトを構成します。 例えば、ユーザーの要求を満たすための関連情報をベクトルDBから取得/順位付けし、プロンプトに挿入する、などです。 この設計も、(エンドユーザーによるものとは違うレイヤの)プロンプトエンジニアリングと言えます。
AI呼び出しの効率化とセキュリティ担保
実際にLLMを呼び出したり、ユーザーにレスポンスを返す時には、以下のような観点が役に立ちます。
- LLMキャッシュ:
LLMキャッシュは、LLMの出力を保存します。 そして似たクエリがLLMに発行される時に、実際にLLMに問い合わせることなく、LLMキャッシュから返答を返します。 これによりレスポンス速度の向上や、リソースコストの削減に繋がります。 GPTcacheのようなツールも参考になるでしょう。 - コンテンツフィルター:
コンテンツフィルターによって、(ユーザーからの悪意ある入力への反応など)不適切な回答をしないよう調整します。 まだ開発初期の段階ですが、llm-prompt-injection-filteringやllm-guardのようなツールが参考になります。 - Telemetry/遠隔監視サービス:
実際に稼動しているアプリケーションで、ユーザーの活動(例: ユーザーがどのくらいの頻度で提案を受け入れたか、など)を収集します。 こうして実稼働の中で集めたユーザーのデータは、アプリを改善するのに役立ちます。 例えばOpenTelemetryなどは、この用途でも使えるオープンソースのテレメトリフレームワークです。
おわりに
以上、GitHubブログの記事から、LLMアプリケーションアーキテクチャの勘所を整理しました。
ざっくりした議論ではありましたが、言語化してみると頭もよりクリアになります。
より詳細が気になる方は、ぜひ元記事を参照ください。
[関連記事]
参考
The architecture of today's LLM applications - The GitHub Blog
Software 2.0. I sometimes see people refer to neural… | by Andrej Karpathy | Medium
A developer's guide to prompt engineering and LLMs - The GitHub Blog