Raspberry Pi上で、カメラ/サーボモーターとChatGPTを組み合わせて簡単な実験を行います。
次回はこちら:
はじめに
ChatGPTを初めて触った時、これはロボットの頭脳として使えるのでは、とピンと来ました。
最小限の世界観を作ってみたので、備忘録を残します。
書いた.
— BioErrorLog (@bioerrorlog) April 20, 2023
ChatGPTをロボットの頭脳にする実験を、一旦ここまで整理.
ChatGPTをロボットの頭脳にする その1: カメラ/サーボモーターとChatGPTを組み合わせる - BioErrorLog Tech Blog https://t.co/1Ql5FIZJsY
ChatGPTとRaspberry Pi/カメラ/サーボモーターを組み合わせる
プロトタイプコンセプト
今回の実験コンセプトはこちら:
- ChatGPTが現実世界の情報を認識する
- ChatGPTが現実世界の次のアクションを自ら決定する
- 1-2を繰り返し、自分が置かれている現実世界の状況をChatGPTが把握する
- 「ねえ今どんな気持ち?」ってChatGPTに聞く
現実世界の次のアクションを"ChatGPT自身が"決定する、というところがこだわりです。
将来的には、ChatGPTを頭脳としてロボットが自由に動き回り、環境を自律的に学習していく、みたいなことが出来たら面白いですね。
構成
ハードウェア
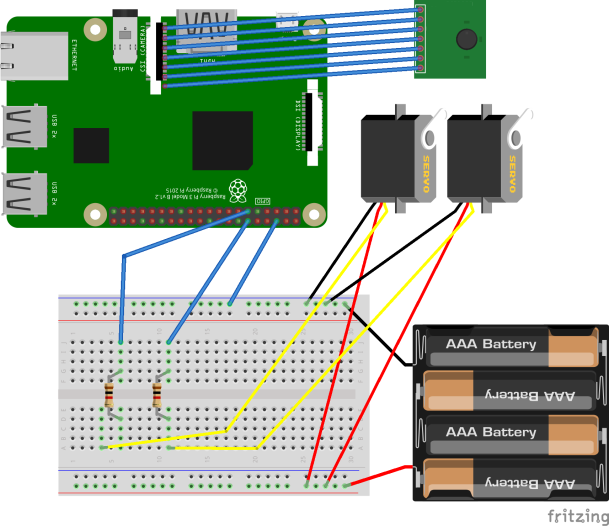
サーボモーター2つとカメラ1つをRaspberry Piに接続しています。
サーボモーターの制御方法は、以前書いたこちらの記事と同様です。
サーボモーターとカメラは、両面テープと輪ゴムでくっつける、という小学生の工作みたいなことをしています。

これで水平方向および垂直方向の首振りと、カメラによる画像取得が可能です。
ソフトウェア
本記事執筆時点のソースコードはこちら:
ざっくり下記の処理を行っています。
- カメラから画像を取得
- 取得画像から物体認識
- 現状のサーボモーターの角度と、画像に映った物体の名前をChatGPT APIに送信
- 次のサーボモーターの角度と、今の気持ち(フリートーク)がChatGPT APIから返される
- ChatGPTが指定した角度に従い、サーボモーターを制御
- 1-5を複数回繰り返す
- 置かれた環境についての説明を求める
一つのポイントは、"次のサーボモーターの角度"をChatGPTに指定させることです。 返答に含まれる値をPython側で解釈し、実際にサーボモーターを制御しています。 画面のあちら側だけの存在だったChatGPTに、現実世界に作用できる手段を与えたみたいで興奮しました。
これは、ChatGPTからの返答をJSON形式に固定させることで実現しています。 (JSONならそのままPythonで容易に解釈できる)
ChatGPTからの返答をJSON形式に固定させるためには、ChatGPT APIのtemperature(回答のランダム性パラメータのようなもの)を低めに設定する必要があります。
今回は0.2に設定して上手く機能しましたが、高め(例えばデフォルトの1.0)に設定すると、指定したJSON形式とは異なる返答がくる場合が出てきます。
もう一つの注意点は、ChatGPT APIからのレスポンスは現状かなり遅い(10-20sec, ひどい時はもっと遅い)、という点です。 これはForumで調べてみても皆同じように言っているのですが、現状は改善を待つことしかできなそうです。
Search results for 'API response too slow' - OpenAI Developer Forum
スムーズにこの首振りロボットを動かすには、なるべくAPIを呼び出す回数を減らす工夫が必要になります。 今回のケースでは、一回の応答の中に"次のサーボモーター角度"の指定を複数回分入れ込ませることで、API応答の待ち時間が毎回発生するのを回避しました。
最終的には、こちらのsystemプロンプトに落ち着きました:
You are a robot with a camera, composed of 2 servo motors: horizontal & vertical.
Horizontal: min -90 right, max 90 left.
Vertical: min -90 down, max 90 up.
Your behavior principles: [curiosity, inquisitiveness, playfulness].
Your answer MUST be in this JSON format: {"NextServoMotor": [{"Horizontal": int(-90~90), "Vertical": int(-90~90)}], "FreeTalk": string}
Constraint: len(your_answer["NextServoMotor"]) == 5
Answer example: {"NextServoMotor": [{"Horizontal": -60, "Vertical": -30},{"Horizontal": 0, "Vertical": 0},{"Horizontal": 90, "Vertical": -45},{"Horizontal": 0, "Vertical": 60},{"Horizontal": -30, "Vertical": -60}],"FreeTalk": "Based on what I've seen, I'm curious about the PC and mouse. I wonder what you use them for and what kind of work or play they are involved in?"}
動作結果
実際にこの"首振りロボット"が動作している様子はこちらです:
ChatGPTのロボット実験その2:
— BioErrorLog (@bioerrorlog) April 16, 2023
ChatGPTにカメラとモーターを組み合わせて、周囲を探索してもらう.
「スマホを持った人間とノートPCがある」としっかり答えてくれた.
いい感じ. https://t.co/igp7T4Pc2y pic.twitter.com/qVHgiEhXkJ
周囲の探索を複数回行った後、置かれている状況を尋ねると下記のような返答が返ってきます。
Based on what I have seen, there are a few objects in the room, including a bottle and a laptop. However, I have not seen much else yet. I am curious to explore more and see what other interesting things I can find!
「これまでに見たものに基づくと、部屋にはボトルとラップトップ等の物がいくつかあります。 しかし、まだそれ以外の物はあまり見てません。 もっと探索して、他にどんな面白いものが見つけられるか楽しみです!」
想定した最小限の世界観を実現できました。
夢が広がります。
課題
最小限の世界観は実現できましたが、もちろん課題がたくさんあります。
物体認識
現状の実装では、物体認識の精度は高くありません。
今回はカメラで取得した画像をYOLOv3で物体認識させています。 実際は周囲の物体を認識できることは稀で、たまに何かを認識する(ほとんど何も認識しない)くらいの挙動です。
画像認識関連に詳しくなかったので、ChatGPTに聞いたりググって出てきたやり方で簡単に実装しましたが、改めて調べてみるとYOLOv3はかなり古いモデルのようです。 新しいモデルを使えば、精度も処理速度も向上するかもしれません。
そもそも、GPTでマルチモーダルが利用可能になれば、取得画像ごとGPTに送って認識させる、という形にできるでしょう。 マルチモーダルの課金体系が良心的であることを祈っています。
Token消費量
現在の実装では、ChatGPT APIから帰ってきたレスポンスは全てassistantプロンプトとして追加しています。 動作を続ければ続けるほど、蓄積されたレスポンス全てをプロンプトに入れ込むので、tokenの消費量は増加していく仕様です。
ちょっとした実験くらいなら無視できるような課金量ですが、今後長く起動し続けるような使い方をしてくならば、今のやり方は現実的ではありません。
レスポンス全てをプロンプトに入れ込むのではなく、重要情報を要約してcontextに入れ込むようにすれば、情報量の喪失を抑えたままtoken消費を軽減できるでしょう。
記憶保持
現在は一連の処理が終われば記憶は残りません。 起動する度にまたゼロから周囲を探索する形になっています。
例えばデータベースを使って外部記憶の仕組みを導入すれば、いわゆる長期記憶的な感じで情報を保持できるようになるでしょう。 長期記憶があれば、遊びの幅が広がります。
外界の認識
現在の実装では、
- サーボモーターの角度 (水平方向および垂直方向)
- 認識された物体名のリスト
の組み合わせを蓄積することで、外界の状況を認識させています。
このやり方でも、結構上手く外界を認識できています。 例えば「周囲にある物を左側から順に説明して」みたいに聞いても、ある程度正しい位置関係で説明が返ってきます。
ただ、もっとChatGPT/LLMならではのやり方が、もっと機械っぽくない良いやり方があると思っています。 物体リストと角度の組み合わせではなく、例えば「周囲の状況を詳細に描写した文章」を記憶の拠り所にする、とかも面白そうですね。 あるいはマルチモーダルが使えるようになったら、もっと自由な手段が取れそうです。
「機械/プログラムを扱っている」という人間側の思い入れが、遊びの幅を狭めてしまうことのないよう気をつけたいところです。
おわりに
以上、ChatGPTをロボットの頭脳にする取り組みの第一弾として、試作したものをまとめました。
昨今のLLMの盛り上がりから、何か面白い物が作れるんじゃないか、という興奮が止みません。
色々実験して遊び倒していきたいところです。
[関連記事]
参考
Search results for 'API response too slow' - OpenAI Developer Forum
GitHub - bioerrorlog/robot-gpt at 85c256e3366f57532e74ee5c1294b69717647df9