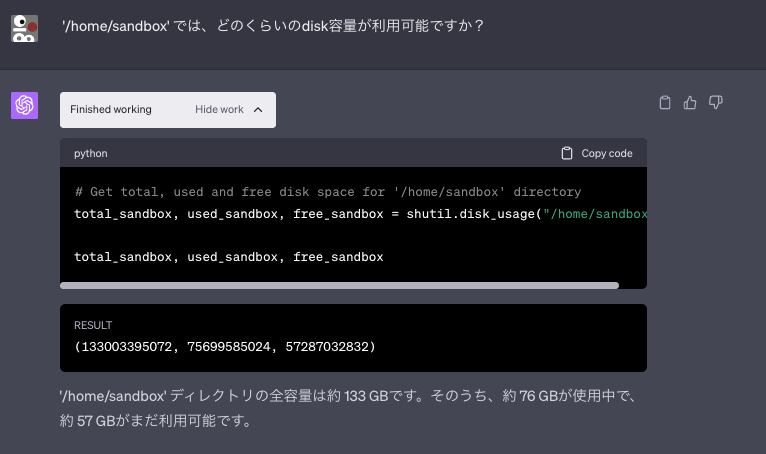
サムアルトマンCEOが取締役会との喧嘩別れで解任されてしまった。
なんということだ。
はじめに
OpenAIのサムアルトマンCEOが、今朝(日本時間で2023/11/18)取締役会から解任されました。
OpenAI DevDayで盛り上がった最中、突然すぎて(私が)混乱しているので、情報を整理します。
OpenAIのサムアルトマンCEOが解任された件
OpenAIからの発表
まずは落ち着いて、OpenAIからの発表を読みます。
openai.com
以下、日本語訳 by ChatGPT
OpenAI、Inc.の取締役会は、OpenAIの全活動の総括的な統治機関として機能する501(c)(3)団体で、本日、サム・アルトマンがCEOを辞任し、取締役会を離れることを発表しました。同社の最高技術責任者であるミラ・ムラティが、即日効力で暫定CEOを務めます。
OpenAIのリーダーシップチームのメンバーであり、5年間勤務しているミラは、OpenAIが世界的なAIリーダーに進化する上で重要な役割を果たしてきました。彼女は独自のスキルセットを持ち、会社の価値観、運営、ビジネスを理解しており、すでに同社の研究、製品、安全機能を率いています。長期にわたる在籍と会社のすべての側面に密接に関わっている経験、およびAIガバナンスとポリシーに関する経験を持つ彼女は、この役割に特に適任であると考えられ、取締役会は、正式なCEOを探す間の移行をスムーズに行うことを期待しています。
アルトマン氏の退任は、取締役会による慎重なレビュープロセスの結果であり、彼が取締役会とのコミュニケーションで一貫して率直でなかったことから、取締役会がその責任を果たすことを妨げたためです。取締役会は、彼がオープンAIを引き続き率いる能力に対する信頼を失いました。
取締役会は声明で次のように述べています。「OpenAIは、汎用人工知能が全人類に利益をもたらすことを保証するという私たちの使命を進めるために意図的に構築されました。取締役会は、この使命に引き続き全力で取り組むことを約束します。私たちは、OpenAIの設立と成長へのサムの多大な貢献に感謝します。同時に、私たちは新しいリーダーシップが必要であると考えています。同社の研究、製品、安全機能のリーダーとして、ミラは暫定CEOとしての役割を果たすために特に適任です。私たちは彼女がこの移行期間中にオープンAIを率いる能力を最大限に信頼しています。」
OpenAIの取締役会は、OpenAIの最高科学者イリヤ・スツケーバー、独立取締役のQuora CEOアダム・D'アンジェロ、技術起業家ターシャ・マッコーリー、およびジョージタウンセンターのセキュリティと新興技術のヘレン・トナーで構成されています。
この移行の一環として、グレッグ・ブロックマンは取締役会の議長を辞任し、CEOへの報告を続ける同社の役割に留まります。
OpenAIは2015年に非営利団体として設立され、人工一般知能が全人類に利益をもたらすことを核とする使命を持っています。2019年、オープンAIは、この使命を追求するための資金調達が可能になるように、非営利団体の使命、ガバナンス、監督を維持しながら、構造を再編しました。取締役会の大部分は独立しており、独立した取締役はOpenAIの株式を保有していません。会社は劇的な成長を遂げていますが、OpenAIの使命を進め、その憲章の原則を維持することは、取締役会の基本的なガバナンス責任です。
人事イベントをピックアップすると、
ですね。
サムアルトマン解任の理由
上記の発表の中で、サムアルトマン解任の理由について触れられているのはこの部分だけです。
アルトマン氏の退任は、取締役会による慎重なレビュープロセスの結果であり、彼が取締役会とのコミュニケーションで一貫して率直でなかったことから、取締役会がその責任を果たすことを妨げたためです。取締役会は、彼がオープンAIを引き続き率いる能力に対する信頼を失いました。
原文:
Mr. Altman’s departure follows a deliberative review process by the board, which concluded that he was not consistently candid in his communications with the board, hindering its ability to exercise its responsibilities. The board no longer has confidence in his ability to continue leading OpenAI.
「取締役会とのコミュニケーションで一貫して率直でなかった」のが理由、と文面上は書かれています。
実際のところ何があったのかは現段階ではわかりませんが、円満な卒業でないことは明らかでしょう。
サムアルトマン本人の反応
CEO解任について、サムアルトマン本人もTwitter(X)でコメントしています。
日本語訳:
オープンAIでの時間はとても楽しかったです。個人的にも変革的な体験であり、少しでも世界に影響を与えることができたかと思います。何よりも、そんな才能豊かな人々と一緒に働けたことが一番の喜びでした。
次に何をするかについては、後ほど詳しくお話しします。
あくまで何が起きたのか、については言及を控えています。
ちなみに、グレッグ・ブロックマンも、暫定CEOに着任するミラ・ムラティも、特に個人的なコメントは現時点では見られません。
追記:グレッグ・ブロックマンがTwitter(X)上で反応しました↓
追記: グレッグ・ブロックマンの反応
日本語訳:
今日のニュースを知った後、これが私が OpenAI チームに送ったメッセージです。
"""
みなさん、こんにちは。
8年前、私のアパートから始めて、一緒に築き上げたものを本当に誇りに思っています。
不可能だと思われた数々の理由にも関わらず、困難な時も素晴らしい時も共に乗り越え、多くのことを成し遂げました。
しかし、今日のニュースを受けて、私は辞任します。
心から、皆さんにとって最高のことが起こることを願っています。私は全人類に利益をもたらす安全なAGIを創造するという使命を信じ続けています。
"""
日本語訳:
サムと私は、理事会が今日行ったことにショックを受け、悲しんでいます。
まず、OpenAI で私たちが協力してきた素晴らしい人々、顧客、投資家、そして手を差し伸べてくれたすべての人々に感謝の意を表しましょう。
私たちも、何が起こったのかを正確に把握しようとしているところです。私たちが知っていることは次のとおりです。
昨夜、サムはイリヤから金曜日の正午に話したいというメールを受け取りました。サムは Google Meet に参加し、グレッグを除く役員全員が参加しました。イリヤはサムに、自分が解雇されること、そしてそのニュースが間もなく発表されることを告げた。
午後 12 時 19 分に、グレッグはイリヤからすぐに電話するよう求めるテキスト メッセージを受け取りました。午後 12 時 23 分に、イリヤは Google Meet リンクを送信しました。グレッグは、自分が取締役会から外されることになり(しかし会社にとって重要な人物であり、その役割は留まる)、サムは解雇されたと告げられた。同じ頃、OpenAI はブログ投稿を公開しました。
私たちが知る限り、前夜に知ったミラ以外の経営陣は、直後にこのことを知りました。
溢れんばかりのサポートは本当に素晴らしいものでした。ありがとう、でも心配するのに時間を費やさないでください。大丈夫です。より素晴らしいものが間もなく登場します。
ということで、サムアルトマンの解任を聞いたグレッグ・ブロックマンは、即座に辞任したようです。
どうなることやら..
追記: 結末
最終的に、サムアルトマンはOpenAIのCEOに復帰しました。
様々なドタバタ劇がありましたが、これで落ち着きそうですね。
openai.com
おわりに
OpenAI DevDayから2週間も経たないうちに、まさかこのような解任劇があるとは思いませんでした。
OpenAIとサムアルトマン氏の今後に幸あれ。
[関連記事]
www.bioerrorlog.work
www.bioerrorlog.work
www.bioerrorlog.work
参考
OpenAI announces leadership transition
https://twitter.com/OpenAI/status/1725611900262588813
https://twitter.com/sama
https://twitter.com/gdb
https://twitter.com/miramurati