GPTにて、テキストのToken数を確認する方法をまとめます。
はじめに
ChatGPTでも使われているGPTシリーズは、その入力テキストを'Token'という単位で処理しています。
OpenAI APIの課金はこのToken単位で行われるので、いかに情報をToken効率良く記載するか、も重要な観点になります。

今回は、このGPTシリーズの実際のToken分割を確認する方法をまとめます。
GPT、日本語は英語の倍近いTokenを消費している、というのがこうして見るとよくわかる.
— BioErrorLog (@bioerrorlog) April 9, 2023
一つの漢字が3つのTokenに分割されてたりするのも面白い.
これほど細切れなToken分割でも上手くいくものなのが不思議に思えてくる.https://t.co/7KynCjrsIR pic.twitter.com/84UNbl9kHc
GPTのToken数を確認する
GUIで確認する | Tokenizer
手軽かつ分かりやすくToken分割を確認できる方法に、OpenAIが提供しているTokenizerというサイトがあります。
テキストを入力するだけで、どの単語がどのようにToken分割されているのかが可視化できます。
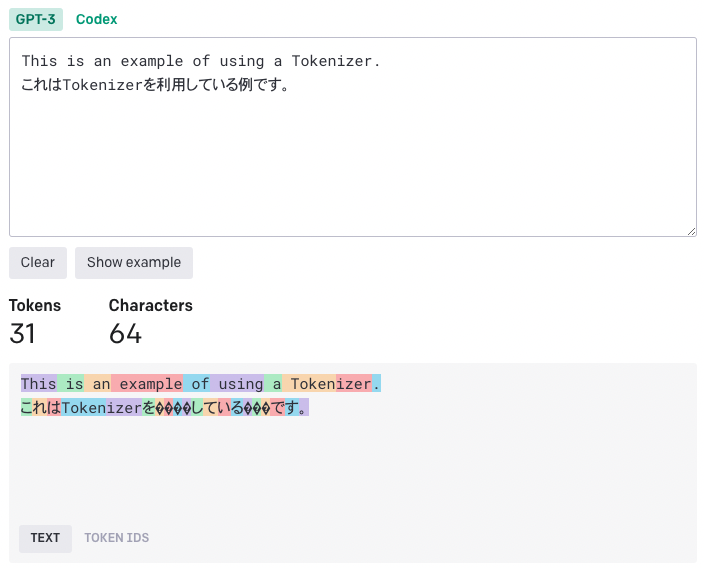
余談ですが、日本語が英語の倍近いToken数を消費していることが分かります。
Pythonで確認する | tiktoken
tiktokenを使うことで、PythonでToken分割を確認することができます。
(先述のTokenizerも内部ではこのtiktokenが使われているようです)
# インストール
pip install tiktoken
テキストのToken数は、例えば下記のようにして取得できます。
import tiktoken def num_tokens_from_string(string: str, model_name: str) -> int: """Returns the number of tokens in a text string.""" encoding = tiktoken.encoding_for_model(model_name) num_tokens = len(encoding.encode(string)) return num_tokens
(コードはOpenAI Cookbookを元に改変)
実行例:
text = "This is an example of using a Tokenizer." # GPT-3でToken数を確認 num_tokens_from_string(text, "gpt-3.5-turbo") # 10 # GPT-4でToken数を確認 num_tokens_from_string(text, "gpt-4") # 10
選択できるモデルと、そこで使われるエンコーディングは以下の通りです。

(gpt-3.5-turboとgpt-4は同じエンコーディングcl100k_baseが利用されているので、先の例でも両者の結果に差は出ていません)
終わりに
以上、GPTのToken分割を確認する方法をまとめました。
いかに少ない文字数(Token数)でこちらの意図を明示するか、というのは、シンプルで綺麗なコードを書く、という行為に似ていて面白いですね。
どなたかの参考になれば幸いです。
[関連記事]
参考
GitHub - openai/tiktoken: tiktoken is a fast BPE tokeniser for use with OpenAI's models.