$ aws sts get-caller-identity
An error occurred (InvalidClientTokenId) when calling the GetCallerIdentity operation: The security token included in the request is invalid
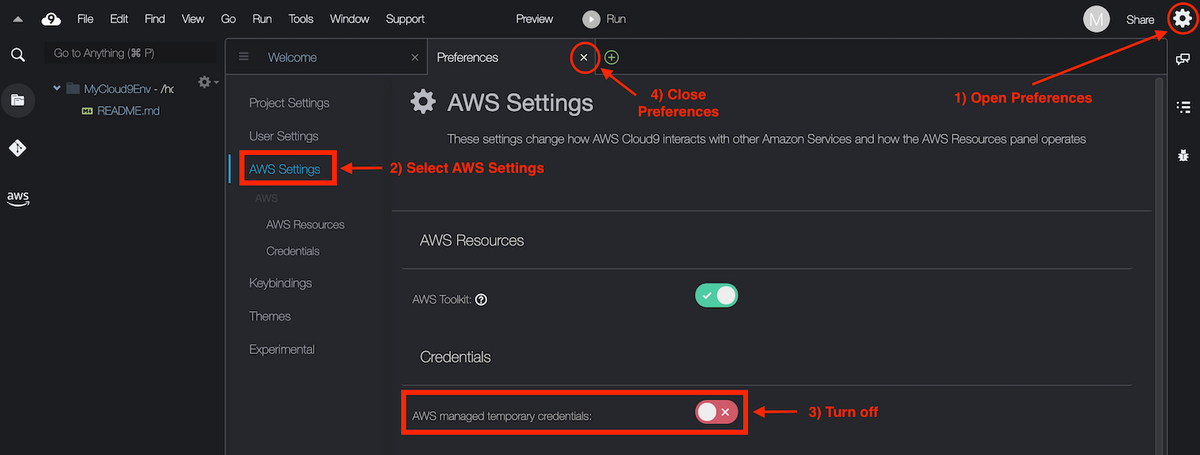
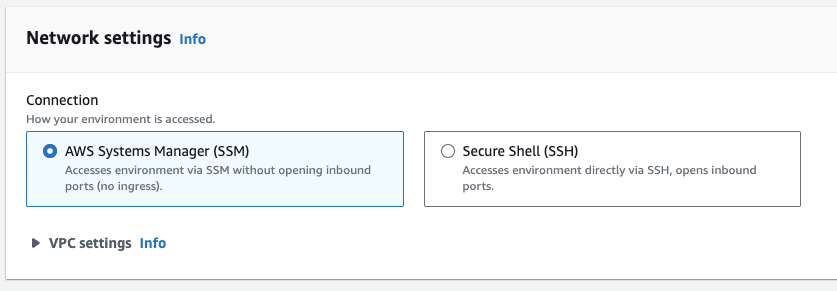
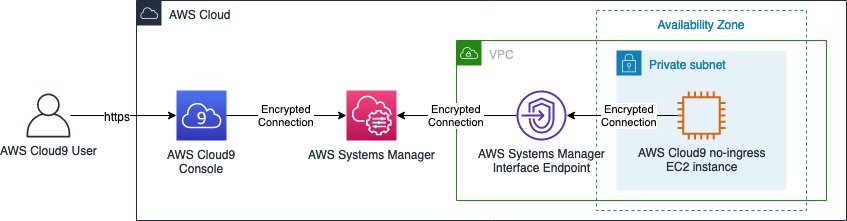
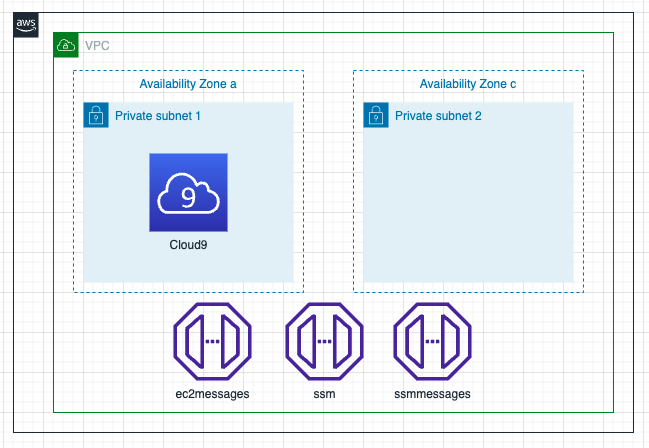
Currently, if your environment’s EC2 instance is launched into a private subnet, you can't use AWS managed temporary credentials to allow the EC2 environment to access an AWS service on behalf of an AWS entity (for example, an IAM user).
// Default to provider current region if no other filters matchedif region == nil {
matchingRegion, err := FindRegionByName(d.Meta().Region)
if err != nil {
response.Diagnostics.AddError("finding Region by name", err.Error())
return
}
region = matchingRegion
}
aws_region data sourceの引数に何も指定がない場合、メタデータからproviderの現在のリージョンが取得されているのがわかります。
AWSTemplateFormatVersion:'2010-09-09'Description:'Create S3 and DynamoDB resources for Terraform backend'Parameters:ResourceNamePrefix:Type: String
Description:'The prefix for the resource names (S3 bucket and DynamoDB table)'Default:'demo'Resources:TerraformStateBucket:Type:'AWS::S3::Bucket'Properties:BucketName:!Sub'${ResourceNamePrefix}-${AWS::AccountId}-terraform-state'VersioningConfiguration:Status:'Enabled'LifecycleConfiguration:Rules:- Id: ExpireNoncurrentVersions
NoncurrentVersionExpirationInDays:90Status: Enabled
BucketEncryption:ServerSideEncryptionConfiguration:- ServerSideEncryptionByDefault:SSEAlgorithm:'AES256'AccessControl:'Private'PublicAccessBlockConfiguration:BlockPublicAcls:trueIgnorePublicAcls:trueBlockPublicPolicy:trueRestrictPublicBuckets:trueDynamoDBLockTable:Type:'AWS::DynamoDB::Table'Properties:TableName:!Sub'${ResourceNamePrefix}-terraform-lock'AttributeDefinitions:- AttributeName:'LockID'AttributeType:'S'KeySchema:- AttributeName:'LockID'KeyType:'HASH'BillingMode:'PAY_PER_REQUEST'Outputs:TerraformStateBucketName:Description:'The name of the S3 bucket for storing Terraform state files'Value:!Ref TerraformStateBucket
DynamoDBLockTableName:Description:'The name of the DynamoDB table for Terraform state locking'Value:!Ref DynamoDBLockTable
#!/bin/bash# check if we need to configure our docker interfaceSAGEMAKER_NETWORK=`docker network ls|grep -c sagemaker-local`if [$SAGEMAKER_NETWORK-eq0];then
docker network create --driver bridge sagemaker-local
fi# Get the Docker Network CIDR and IP for the sagemaker-local docker interface.SAGEMAKER_INTERFACE=br-`docker network ls|grep sagemaker-local | cut -d'' -f1`DOCKER_NET=`ip route |grep$SAGEMAKER_INTERFACE| cut -d"" -f1`DOCKER_IP=`ip route |grep$SAGEMAKER_INTERFACE| cut -d"" -f9`# check if both IPTables and the Route Table are OK.IPTABLES_PATCHED=`sudo iptables -S PREROUTING -t nat |grep -c $SAGEMAKER_INTERFACE`ROUTE_TABLE_PATCHED=`sudo ip route show table agent |grep -c $SAGEMAKER_INTERFACE`if [$ROUTE_TABLE_PATCHED-eq0];then# fix routing
sudo ip route add $DOCKER_NET via $DOCKER_IP dev $SAGEMAKER_INTERFACE table agent
echo"route tables for Docker setup done"elseecho"SageMaker instance route table setup is ok. We are good to go."fiif [$IPTABLES_PATCHED-eq0];then# fix ip table
sudo iptables -t nat -A PREROUTING -i$SAGEMAKER_INTERFACE-d169.254.169.254/32-p tcp -m tcp --dport80-j DNAT --to-destination169.254.0.2:9081
echo"iptables for Docker setup done"elseecho"SageMaker instance routing for Docker is ok. We are good to go!"fi
重要なのは下記2つの設定変更部分です。
# fix routing
sudo ip route add $DOCKER_NET via $DOCKER_IP dev $SAGEMAKER_INTERFACE table agent
# fix ip table
sudo iptables -t nat -A PREROUTING -i$SAGEMAKER_INTERFACE-d169.254.169.254/32-p tcp -m tcp --dport80-j DNAT --to-destination169.254.0.2:9081
SageMaker SDKのlocal training jobでは、sagemaker-localという名前のdocker networkが利用されます (存在しない場合は作成する処理をスクリプト冒頭で行っています)。
$ cargo lambda new lambda
? Is this function an HTTP function? No
? AWS Event type that this function receives
activemq::ActiveMqEvent
autoscaling::AutoScalingEvent
chime_bot::ChimeBotEvent
cloudwatch_events::CloudWatchEvent
cloudwatch_logs::CloudwatchLogsEvent
cloudwatch_logs::CloudwatchLogsLogEvent
v codebuild::CodeBuildEvent
[↑↓ to move, tab to auto-complete, enter to submit. Leave it blank if you don't want to use any event from the aws_lambda_events crate]
// main.rsuselambda_runtime::{run, service_fn, Error, LambdaEvent};
useserde::{Deserialize, Serialize};
/// This is a made-up example. Requests come into the runtime as unicode/// strings in json format, which can map to any structure that implements `serde::Deserialize`/// The runtime pays no attention to the contents of the request payload.#[derive(Deserialize)]structRequest {
command: String,
}
/// This is a made-up example of what a response structure may look like./// There is no restriction on what it can be. The runtime requires responses/// to be serialized into json. The runtime pays no attention/// to the contents of the response payload.#[derive(Serialize)]structResponse {
req_id: String,
msg: String,
}
/// This is the main body for the function./// Write your code inside it./// There are some code example in the following URLs:/// - https://github.com/awslabs/aws-lambda-rust-runtime/tree/main/examples/// - https://github.com/aws-samples/serverless-rust-demo/
async fnfunction_handler(event: LambdaEvent<Request>) ->Result<Response, Error> {
// Extract some useful info from the requestlet command = event.payload.command;
// Prepare the responselet resp = Response {
req_id: event.context.request_id,
msg: format!("Command {}.", command),
};
// Return `Response` (it will be serialized to JSON automatically by the runtime)Ok(resp)
}
#[tokio::main]
async fnmain() ->Result<(), Error> {
tracing_subscriber::fmt()
.with_max_level(tracing::Level::INFO)
// disable printing the name of the module in every log line.
.with_target(false)
// disabling time is handy because CloudWatch will add the ingestion time.
.without_time()
.init();
run(service_fn(function_handler)).await
}
Phase context status code:
YAML_FILE_ERROR Message: Expected Commands[0] to be of string type: found subkeys instead at line 6, value of the key tag on line 5 might be empty